


Designing an Agent Reading Test
In which I try to give people tools to understand how agents read web content, and where they fail.
I've been writing a lot about agents and docs lately, and one thing I keep bumping into in conversations is confusion about what "AI-friendly docs" actually means. Someone says their leadership has mandated that docs need to be optimized for AI, and when I ask what that means in practice, the answer is usually some variation of "I don't know, they just said AI." And honestly? I get it. "AI" is doing a lot of heavy lifting as a term right now, and it's papering over a distinction that really matters if you're trying to figure out what to actually do with your documentation.
So let's talk about that distinction. Because when someone says "AI needs to consume our docs," there are two very different things they might mean, and what you should prioritize depends entirely on which one they're talking about.
There are two primary ways that AI systems consume documentation today:
Model training: Companies like Anthropic, OpenAI, and Google crawl the web (including your docs) and use that content as training data for their large language models. This is the bulk ingestion pipeline. Your docs go in, and months later, the model "knows" things that were in your docs. I've started using "LLM" as shorthand for this consumer when talking to stakeholders, because it's probably a term they're already familiar with and they probably already have some idea that this is an extant process.
Agent workflows: A developer is using a coding agent like Claude Code, Cursor, or GitHub Copilot. The agent needs to check an API signature or verify some syntax right now, so it fetches your docs page in real time, reads it, and uses the information to help the developer with their task.
These two consumers require docs to support their distinct consumption patterns. They have different constraints, different failure modes, and different implications for how you structure your content. But they get lumped together under the same "AI-friendly" umbrella, and that's where the confusion starts.
When a model provider crawls your docs for training, here's roughly what happens. A crawler visits your site, pulls down your pages, and feeds that content into a training pipeline along with billions of other pages from across the internet. The model learns patterns from all of that data. Months later, when someone asks the model about your product, it can answer based on what it absorbed during training.
From a docs perspective, this is the consumption pattern that most closely resembles traditional SEO thinking. The crawler visits your pages, and the content on those pages becomes part of the model's knowledge. Things that matter here:
Many of us are already familiar with this pipeline, at least in broad strokes. It's been discussed extensively since ChatGPT brought LLMs into mainstream awareness. And a lot of the "AI-friendly docs" guidance that's been circulating focuses on this use case: make sure your content is crawlable, use clear structure, keep things up to date. All solid advice.
But this is not the only way AI consumes docs anymore. And I'd argue it's not even the most urgent one for docs teams to think about.
Here's where things get interesting for documentarians, and where I think a lot of the confusion lives.
When a developer uses a coding agent, the agent doesn't rely solely on its training data. It can go look things up. The agent fetches your docs page in real time, reads the content, and uses it to help the developer right now. This is a different access pattern from model training, and it introduces a completely different set of challenges.
I wrote in detail about what this looks like in practice in my Agent-Friendly Docs article. But the short version is: agents access your docs more like a human user would, except with a bunch of limitations that humans don't have.
A human visits a docs page and sees the rendered result. They scroll, they click tabs, they follow links, they use the table of contents. They can skim a long page and find the section they need. They have a browser that renders JavaScript, follows redirects transparently, and handles authentication flows.
An agent fetches the raw content of a URL and tries to extract information from it. Depending on the platform, it might get HTML (with all the CSS and JavaScript noise), or it might get markdown if the site supports it. The content often goes through a truncation step or a summarization model before the agent ever sees it. The agent can't click tabs. It can't render JavaScript. It can't always follow redirects. And if your page is too long, the agent might only see the first third of it, with no indication that anything was cut.
This is a different consumer than a training crawler. The crawler visits once, ingests everything, and moves on. The agent visits in the moment, needs specific information now, and is constrained by context windows, truncation limits, and processing pipelines that vary by platform.
If you're a docs team that's been told to make your docs "AI-friendly," the work you do looks very different depending on which consumer you're optimizing for.
To be clear, these two consumers aren't in conflict. A lot of what makes docs good for one also makes them good for the other. Clear writing, logical structure, accurate content: these are universally good. But the specific optimizations diverge, and if you only think about one consumer, you'll miss important work for the other.
The training pipeline cares about your content being accessible to crawlers and being a good representation of your product's capabilities and APIs. The agent pipeline cares about your content being accessible in the moment, at a reasonable size, in a format the agent can actually parse.
If your leadership tells you "make docs AI-friendly" and you spend all your time on crawlability and robots.txt, you've addressed the training pipeline but potentially missed the agent pipeline entirely. If you focus exclusively on page size and markdown rendering, you've optimized for agents but may have overlooked whether your content is even reaching training pipelines.
If you're trying to figure out where to focus first, here's my honest assessment. Training pipeline optimization is important but slow-moving. The feedback loop is measured in months, the patterns are relatively well understood, and a lot of the work (clear writing, good structure, not blocking crawlers) overlaps with existing docs best practices.
Agent optimization is more urgent and less well understood. Agents are being adopted fast, the consumption patterns are still being discovered, and the failure modes are often invisible. A developer's agent silently gets truncated content from your docs page, produces an incorrect answer, and neither the developer nor you ever know about it. That's happening right now, at scale, across the industry.
So if you're just starting to think about this:
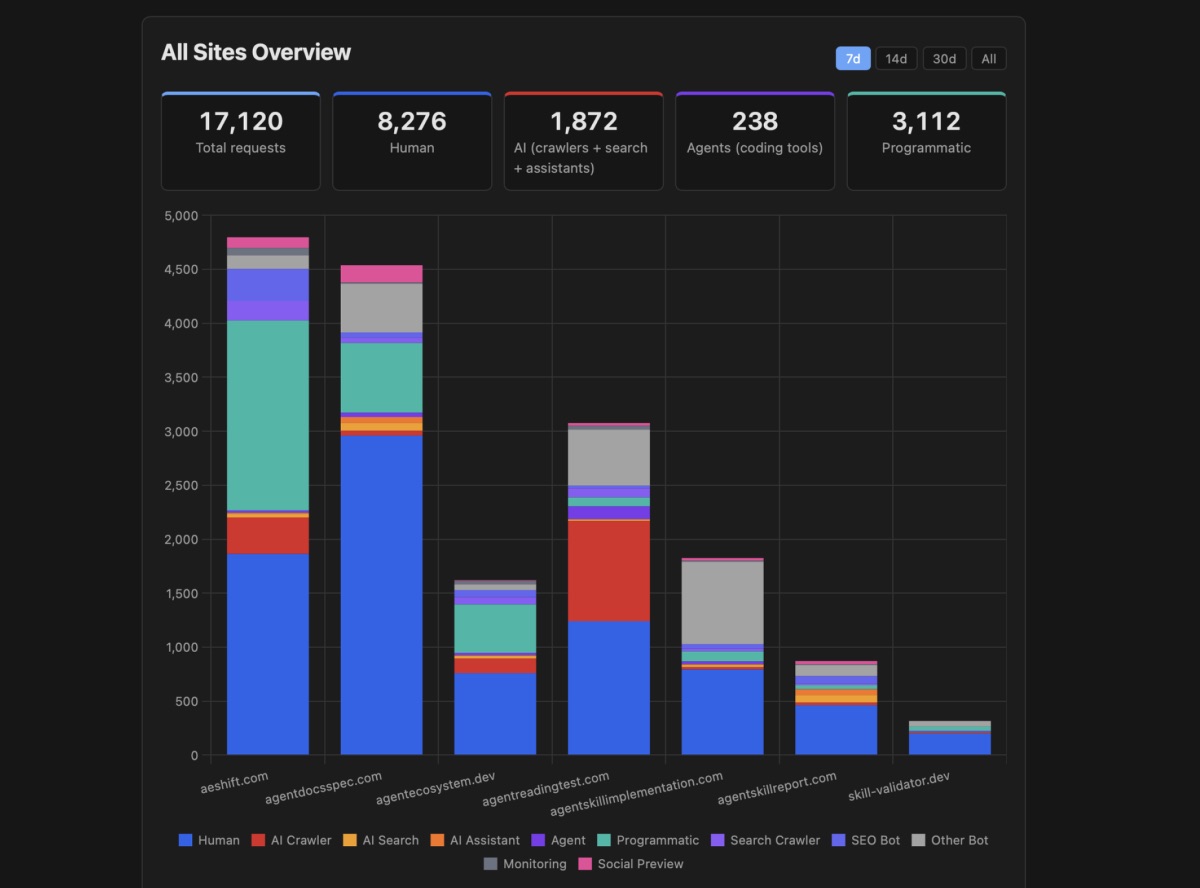
If you want a more structured framework for evaluating your docs, the Agent-Friendly Documentation Spec defines 21 checks across 8 categories that cover the agent-side optimizations I've been describing: llms.txt discovery, markdown availability, page size, content structure, URL stability, and more. It's based on the real-world agent access patterns I've been researching, and it's designed to give docs teams a concrete checklist instead of a vague "make it AI-friendly" mandate.
And if you want to skip the manual audit and just test your site, I've been building afdocs, a CLI tool that runs those checks automatically against your docs. Point it at your docs URL with npx afdocs check https://docs.example.com and it'll tell you where you stand. It's still early (v0.x), but the checks that are implemented today cover the highest-impact areas: llms.txt validation, markdown availability, page size risks, and content negotiation.
This is the first in what I expect to be a series of posts aimed at helping folks who are navigating the "make docs AI-friendly" mandate without a clear map. If you have questions about any of this, or topics you'd like me to dig into next, I'd love to hear from you.
In which I try to give people tools to understand how agents read web content, and where they fail.
In which I revisit measuring agent web traffic, and dive deeper down the rabbit hole.
In which I share research about why LLM-generated output is hard to fact check.

{kind=link}