

A Skill is More than Markdown
In which I work through the actual lifecycle of an official company skill, and find at least six roles that don't exist in most org charts yet.
If you're a documentation team trying to figure out what "agent-ready" means for your site, you've probably noticed that several different organizations are now offering to score you. Cloudflare just launched isitagentready.com. Fern has an Agent Score directory powered by my Agent-Friendly Documentation Spec and its CLI tool, which runs 22 checks against any docs site. There will probably be more by the time you read this.
Each of these tools produces a number. Numbers are comforting. They give you something to put in a slide deck and something to improve quarter over quarter. But if you're making decisions about where to spend your team's time based on these numbers, you need to understand what each score actually measures. They're not measuring the same thing, and the gaps can be dramatic.
I ran both tools against this site. AFDocs gives it 100/100 (A+): every page renders server-side, serves clean markdown via both URL variants and content negotiation, has a well-structured llms.txt with 100% sitemap coverage, and all content fits comfortably within agent truncation limits.
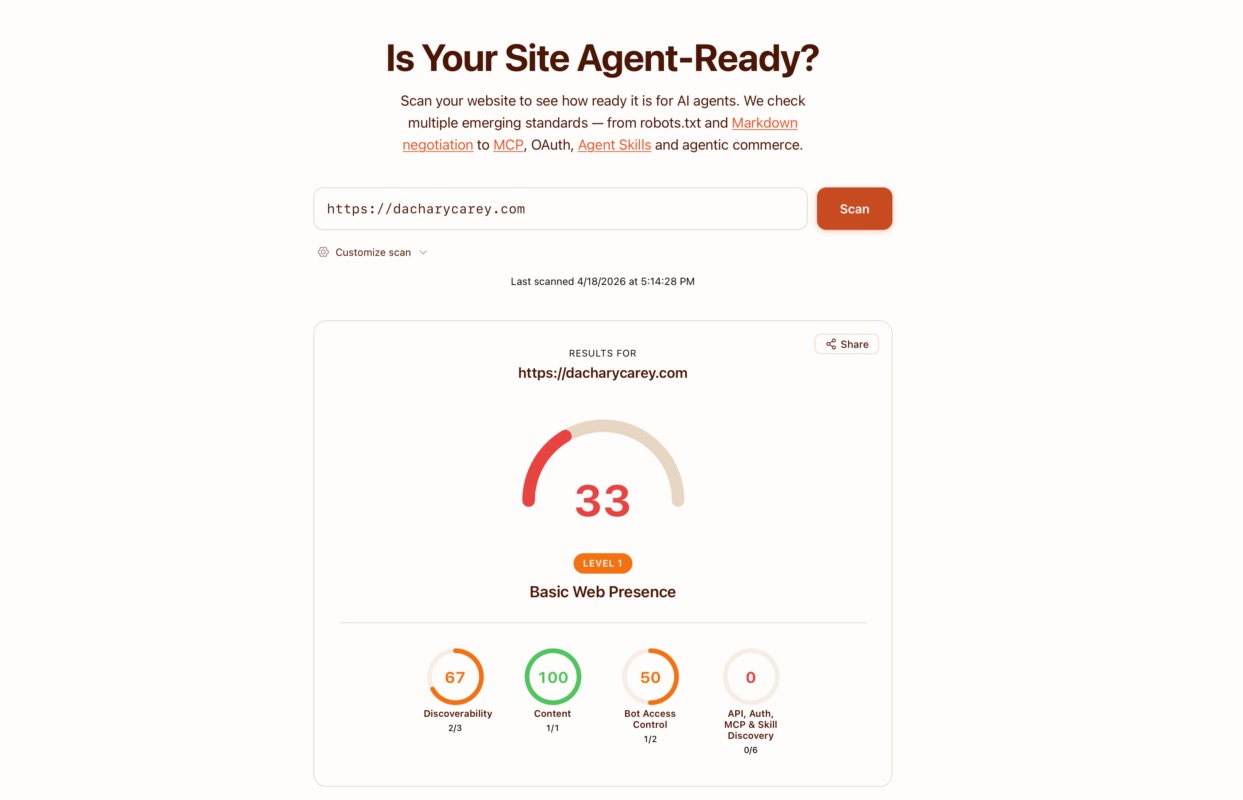
Cloudflare gives it a 33 ("Level 1: Basic Web Presence"). Cloudflare's Content category scores 100, confirming that agents can read the site. But Discoverability drops to 67 because the site doesn't serve RFC 8288 Link headers, Bot Access Control scores 50 because there are no Content Signals in robots.txt, and API, Auth, MCP & Skill Discovery scores 0 out of 6 because the site doesn't implement MCP Server Cards, API Catalogs, OAuth discovery, Agent Skills, or Web Bot Auth. The site that coding agents can read perfectly is, according to Cloudflare, barely agent-ready.
So my question is: which score tells you something useful about your audience?
The various scoring tools roughly cluster into three dimensions of "agent-readiness." Understanding these categories is more useful than comparing raw numbers across tools, because a high score in one dimension doesn't compensate for a low score in another.
When a coding agent fetches one of your documentation pages, does it get usable content? Or does it get 500KB of inline CSS, an empty SPA shell waiting for JavaScript execution, or a page so long that two-thirds of it gets silently truncated before the agent ever sees it?
Content accessibility checks include things like:
Accept: text/markdown) or URL variants (.md appended)?The Agent-Friendly Documentation Spec focuses heavily here, and Fern's Agent Score directory runs these same checks via afdocs under the hood. If your score is high on afdocs, agents can probably find and read your content. That's important when a company like Mintlify reports that 50% of documentation traffic is agent traffic.
This dimension asks whether your site implements web standards that have been proposed for agent interaction. Some are established RFCs; others are draft proposals or single-company initiatives. Whether the ecosystem will actually converge on them is an open question.
Protocol adoption checks include things like:
.well-known/mcp/server-card.json describing your MCP server)Cloudflare's isitagentready.com focuses here, alongside some content checks. If your score is high on Cloudflare, your site has adopted a set of web standards that may become important as the agent ecosystem matures. But as I'll show below, how much they matter today is a different question.
This is the dimension that matters most to your users and that no scoring tool fully captures yet. When a developer using Claude Code, Cursor, or Copilot asks their agent to help with your API, does the agent produce correct, working code? The answer depends on factors that go beyond both content accessibility and protocol adoption:
My Agent-Friendly Documentation Spec tries to cover parts of all three dimensions, but it leans most heavily into the first and third. It checks content-start-position, truncation risk, SPA rendering, llms.txt size limits with defined thresholds, and markdown content parity, all things that determine whether an agent can actually use what it fetches.
I'm working on a new research project that measures agent task completion rates with and without documentation content in-context. I hope to share the results in the next few months. I should know more then about how much the Agent-Friendly Documentation Spec actually correlates with agent task completion success. But this is the ultimate question we should all be striving to answer.
Here's a comparison of what the two scoring approaches check. The gaps matter as much as the coverage.
| Check | AFDocs / Fern Agent Score | Cloudflare isitagentready |
|---|---|---|
| llms.txt exists | Yes, with 5 sub-checks | Optional (off by default) |
| llms.txt size limits | Yes (50K threshold) | No |
| llms.txt freshness | Yes (compares against sitemap) | No |
| Markdown availability | Yes (URL support + content negotiation) | Yes (content negotiation) |
| Markdown-HTML content parity | Yes | No |
| Content-start-position | Yes | No |
| Truncation risk | Yes | No |
| SPA/client-side rendering | Yes | No |
| Code fence validity | Yes | No |
| robots.txt for AI bots | No | Yes |
| Content Signals | No | Yes |
| MCP Server Card | No | Yes |
| API Catalog (RFC 9727) | No | Yes |
| OAuth discovery | No | Yes |
| HTTP status codes | Yes | No |
| Redirect behavior | Yes | No |
A site that scores perfectly on Cloudflare could still be delivering empty SPA shells to coding agents, truncating pages so the agent sees a third of the content, or burying documentation under 80% navigation chrome. Those are the failure modes that determine whether a developer's agent session actually succeeds or fails, and Cloudflare's tool doesn't measure them.
Conversely, a site that passes every afdocs check might not have Content Signals in its robots.txt or an MCP Server Card. Whether those omissions matter depends on what those protocols actually do for agents today. Let's find out.
Cloudflare's scoring tool checks for a set of protocols in its Bot Access Control and Capabilities categories. If your site fails these checks, isitagentready.com tells you to implement them and provides prompts to hand to your coding agent. Before you do that, it's worth understanding what these protocols are, who created them, and whether anything your users run actually consumes them.
It's also worth noting what Cloudflare means by "agent standards." Their Radar dataset tracks "Adoption of AI agent standards" and states they've excluded categories "not meaningful for agent readiness analysis." But several of the standards they include aren't agent standards at all. robots.txt and sitemap.xml are for crawlers and search engines. AI rules in robots.txt govern training crawlers like GPTBot and ClaudeBot, not coding agents.
As I've written about before, coding agents are HTTP clients making targeted requests during development sessions; they don't check robots.txt or parse sitemaps. Labeling crawler infrastructure as "agent standards" makes it harder for documentation teams to understand which audience they're actually serving.
I investigated each protocol that Cloudflare's tool checks for in the Bot Access Control and Capabilities categories. Many of them rely on the .well-known URI pattern (RFC 8615), a legitimate web standard that powers important infrastructure like ACME challenges for TLS certificates. It was authored by Mark Nottingham, who is now Cloudflare's Standards Lead; the pattern predates his time at Cloudflare. Here's what I found about each protocol.
| Standard | Origin | Do coding agents use it? | Adoption |
|---|---|---|---|
| Content Signals | Created by Cloudflare employees (Tremante, Romm). IETF draft expired; not adopted by the AIPREF working group. | No coding agent checks Content Signals. No major crawler has confirmed they respect them. | 3.8M domains, but almost entirely because Cloudflare auto-generates the directive in their managed robots.txt product. |
| RFC 8288 Link headers | Mark Nottingham (Cloudflare Standards Lead). Published 2017. | I've seen no evidence that any coding agent parses HTTP Link headers for resource discovery. | The standard itself is well-established, but agent consumption is zero. |
| Web Bot Auth | Thibault Meunier (Cloudflare). Reference implementation by Cloudflare. | No coding agent signs its requests. A handful of browser automation tools do (Anchor, Browserbase, OpenAI Operator). | Verification exists at WAF layer (Cloudflare, AWS, Akamai). Signing adoption is minimal. |
| MCP Server Card | Community/Anthropic draft. Not merged into the MCP spec. | No coding agent auto-discovers MCP servers. All MCP servers are manually configured by users. | < 15 sites out of 200K scanned. |
| API Catalog (RFC 9727) | Kevin Smith (Vodafone). Published January 2025. | No coding agent checks /.well-known/api-catalog. |
Near zero. |
| Agent Skills index | Cloudflare proposal. | No coding agent checks for it. | Near zero. |
The pattern is clear: not one of these protocols is consumed by any coding agent today. These are standards that either don't exist yet (MCP Server Card is still a draft proposal), have near-zero adoption (API Catalog and Agent Skills), or are authored and promoted by Cloudflare itself (Content Signals, Web Bot Auth, Agent Skills index).
Content Signals deserves a closer look because its adoption numbers seem impressive until you understand the mechanism. Cloudflare reports 3.8 million domains with Content Signals. That number comes from Cloudflare's managed robots.txt product, which auto-generates Content-Signal: search=yes, ai-train=no directives for customers who enable it. That's not 3.8 million site owners independently evaluating and adopting a standard. It's a product feature toggled on. Meanwhile, the IETF draft that would have formalized Content Signals as a standard expired in April 2026 without being adopted by the AIPREF working group, which is producing its own vocabulary spec instead.
Some of these standards address real future problems. Web Bot Auth could matter as agent traffic increases and sites need to verify who's making requests. MCP Server Cards could matter if agents start auto-discovering tools instead of requiring manual configuration. But "could matter" is different from "matters today."
I've checked this against my own data. The Agent Reading Test was posted to Hacker News and received substantial traffic, including significant agent traffic that I've been classifying and analyzing. If coding agents were probing for these .well-known endpoints, this is the kind of site where you'd expect to see it.
Across my server logs, there were 20 total requests to .well-known paths. Here's what was actually requested:
| Path | Count | Requester |
|---|---|---|
/.well-known/traffic-advice |
9 | Chrome Privacy Prefetch Proxy |
/.well-known/nodeinfo |
3 | Mastodon/ActivityPub federation |
/.well-known/security.txt |
2 | Firefox, a contact-scan bot |
/.well-known/ai-plugin.json |
1 | Firefox |
/.well-known/trust.txt |
1 | Firefox |
/.well-known/dnt-policy.txt |
1 | Firefox |
/.well-known/gpc.json |
1 | Firefox |
/.well-known/assetlinks.json |
1 | Firefox |
/.well-known/openid-configuration |
1 | Firefox |
Every request returned 404, because my site doesn't implement any of these URIs. Not one of the agent-related .well-known endpoints that Cloudflare scores on was requested: no mcp/server-card.json, no api-catalog, no agent-skills/index.json, no http-message-signatures-directory. The .well-known requests I received were browser privacy infrastructure, ActivityPub federation, and security contact discovery. Standard web plumbing, nothing agent-related.
The one adjacent signal: a slopsearch/1.0 bot sent a Signature-Agent header referencing its own /.well-known/http-message-signatures-directory, which is the Web Bot Auth pattern. One bot signing its own requests is not the same as agents probing your site for these endpoints.
When a scoring tool gives you points for implementing a standard that fewer than 15 sites in a 200k sample size have adopted, that no coding agent checks for, and that doesn't appear in real-world agent traffic data, what is that score telling you? It's telling you about protocol-readiness for a future that hasn't arrived. That's useful context if you're planning a long-term infrastructure roadmap. It's misleading if you're a documentation team trying to figure out what to work on this quarter.
This isn't a criticism; it's just how incentives work. Every scoring tool was built by an organization with its own perspective, and understanding those perspectives helps you evaluate the scores.
Cloudflare is an infrastructure company whose scoring tool emphasizes protocols that map to its products, as I detailed above. That said, their work on their own documentation is worth learning from. They credit the Agent-Friendly Documentation Spec, did empirical benchmarking, tested which agents actually send content negotiation headers (only 3 of 7), and implemented practical solutions like per-product llms.txt files and /index.md URL fallbacks. The docs work is sound; it's the Cloudflare scoring framework that prioritizes protocol adoption over agent experience.
My spec is built on observed agent behavior from months of hands-on testing, and it reflects my priorities: whether coding agents can actually use documentation to produce correct code. The spec doesn't cover MCP Server Cards or Content Signals because those things don't affect whether Claude Code can read your API reference page. That's a deliberate scoping decision, not a claim that those standards are worthless. Fern chose to use afdocs to power their Agent Score directory specifically because they wanted the scoring to be community-driven by someone without a financial interest in any particular platform. That's an intentional structural choice: rather than building a proprietary scoring tool shaped by their product priorities, they adopted an independent spec.
Understanding who built a tool and why helps you evaluate whether its scores align with your goals. Ask yourself: does my documentation team's success depend on protocol adoption, or on whether agents can actually read and use your pages? The answer shapes which scores to prioritize.
Documentation teams have finite time. Here's how I'd suggest thinking about where to spend it.
If agents can't see your content (SPA rendering, extreme truncation, content buried under chrome), fix that first. Nothing else matters until agents can actually read your pages. No score on any tool compensates for invisible content.
If agents can see your content but can't find it (no llms.txt, stale links, no markdown availability), fix discovery and format next. These are the content accessibility checks that the Agent-Friendly Docs Spec covers.
If content is visible and discoverable, then consider the protocol layer. Markdown content negotiation is the highest-value protocol adoption because it directly improves the content agents receive. Beyond that, don't implement standards just because a scoring tool gives you points for them. When agents start consuming those protocols, you'll know because it'll show up in your traffic logs.
Test with your actual audience. The agents your users run are the ones that matter. Have someone on your team use Claude Code or Cursor against your docs and watch what happens. Does the agent find the right page? Does it see the full content? Does it produce correct code? That 30-minute exercise will tell you more about your agent readiness than any scoring tool.
In which I work through the actual lifecycle of an official company skill, and find at least six roles that don't exist in most org charts yet.
In which I discover that a skill made LLM output 66% worse, and dig into why authoring official skills is a full product lifecycle, not a deliverable.
In which Astro removes its llms.txt entirely, and I explore the result.


{kind=link}