


Filtering AI News
In which I build a system to filter AI-related content.
I wrote the other day about the AI news gathering pipeline I set up that collects and tags news items for different downstream consumers. One of those downstream sources is my new blog, aeshift.com. I wanted the site to have an editorial voice and lens serving practitioners - software developers and people in the tech industry who need to understand how developments in the agent ecosystem affect the actual work they're doing. We know the face of tech is changing at light speed, and I wanted to help practitioners think about how to apply these changes.
I also wanted to experiment with having AI draft the content. Could I convince AI to write useful content with minimal input from me? Could it provide a novel editorial take on news items? Could it produce accurate articles? Could I edit out the inevitable AI writing ticks from what it could produce?
A month into the experiment, here are some stats to whet your appetite:
So what does it look like to have AI write editorial content today?
The previous article covered the news-gather pipeline that collects and tags content from RSS feeds, arXiv, and GitHub releases. Items tagged shift (opinion pieces, product launches with strategic implications, feature releases introducing substantive new capabilities) flow into a second pipeline called shift-sourcing. This is where raw news items become article drafts.
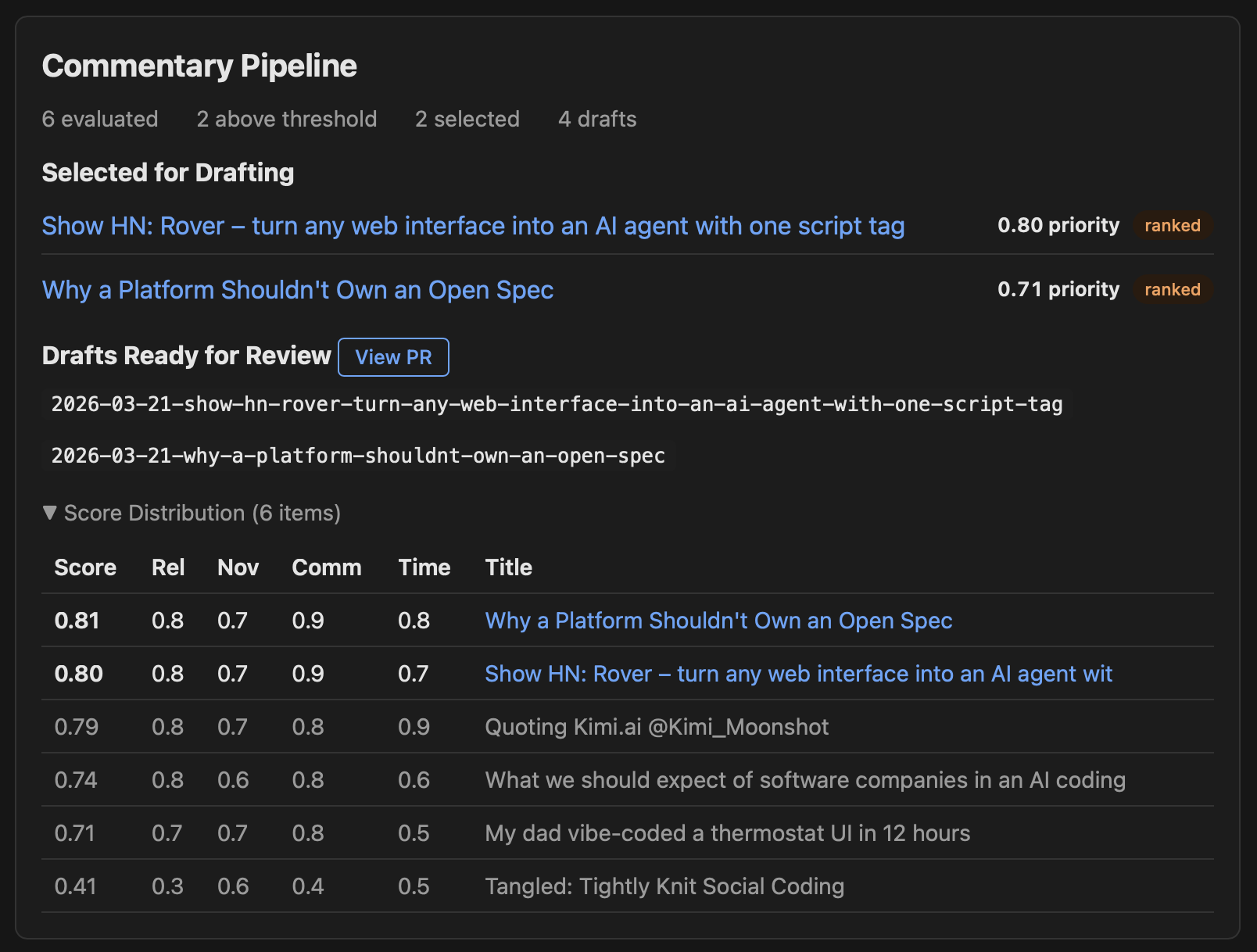
Shift-sourcing has seven stages, each handled by a separate step in the pipeline:
Evaluate. Each tagged item gets scored by Claude Sonnet on four criteria: relevance to practitioners (35% weight), commentary potential (35%), novelty (20%), and timeliness (10%). The scoring rubric is calibrated so that only about 20-30% of items score above 0.7 on any single criterion. Routine tool announcements typically land around 0.4-0.5. Items with high relevance but low timeliness get flagged as evergreen candidates for slow news days. I set these threshholds partially because there's too much content, and I can't care about all of it. I only want to publish one article a day, at most. So I'd rather be selective.
Select. The top-scoring items (above a 0.80 threshold) get selected, with a diversity penalty that reduces scores when too many items cluster from the same source. A duplicate detector compares word overlap against a rolling 30-day history to avoid covering the same ground twice. If there aren't enough items above the threshold, the pipeline recalls recently selected but undrafted items from the last three days, then falls back to the evergreen backlog. There's also a manual queue where I can pin specific items that I want covered regardless of their scores. Default selection is three items per run.
Landscape scan. For each selected topic, the pipeline searches Google News via the Serper API for existing coverage, then summarizes what angles are already out there and what practitioner-relevant angles haven't been explored. If a topic already has deep practitioner-focused commentary, it gets flagged to skip. This is what keeps the site from producing "me too" takes on stories that five other outlets already covered well.
Draft. This is the expensive step. Each topic gets drafts from two models in parallel: Claude Opus and GPT 5.2. The drafting prompt includes an editorial style guide, few-shot examples from previously published articles, the full source content (up to 12,000 characters), and the landscape context showing what angles already exist and which ones are uncovered. The instructions are specific: lead with an opinionated take, not a summary. Stay between 300-800 words. Ground everything in the source material.
Verify. Claude Sonnet fact-checks each draft against the original source, flagging unsupported claims, overstated generalizations, mischaracterizations, and speculation presented as fact. The flags get inserted as inline HTML comments (<!-- VERIFY: ... -->) with the exact quote, what's wrong with it, what the source actually says, and a suggested fix.
Edit. A copy-editing pass targets common LLM writing tics: intensifier crutches ("fundamentally," "essentially," "incredibly"), filler hedging ("it's worth noting that," "interestingly"), empty transitions ("This is significant because"), and generic closers ("only time will tell"). The editing model is prohibited from changing arguments, adding new ideas, or restructuring the article. It just tightens the prose.
Output. The pipeline writes Hugo-ready markdown files with front matter into a draft directory, pushes a branch to the aeshift repo, and opens a PR. By the time I sit down with my morning coffee, I have a PR with two competing drafts per topic, each fact-checked and copy-edited, waiting for my review.
The whole chain runs daily on a self-hosted GitHub Actions runner. News-gather fires at 06:00 UTC, shift-sourcing follows at 06:40, and the PR is usually ready by 07:00. Total API cost for the full pipeline averages about 40-60 cents per run, which is where that $12 monthly figure comes from.
The pipeline also prepares a summary for my daily report, with links to all the news items that were considered for a daily run, so I can click through and check any of them out - and a link to the PR draft.
Here's where the "minimal input from me" aspiration collides with reality. The pipeline delivers draft PRs every morning. What happens next is the most time-consuming part of the operation, and even with some Skills to help me, it's largely a manual process.
I've saved notes to walk you through two real editing sessions to show what this looks like in practice.
The pipeline delivered two drafts based on a Hacker News post about Agent Shield, a macOS daemon for OS-level monitoring of coding agents. Using the select-draft skill I wrote, Claude selected the GPT 5.2 draft for its stronger practitioner framing and better nuance. Opus had punchier individual lines but leaned on hyperbole ("security theater," "useless") and unsupported generalizations. This has been pretty consistent across all of the drafts; for 19 out of 20 articles, GPT 5.2 has had the far stronger editorial takes.
Next, the verification rounds started.
Both drafts contained inline <!-- VERIFY: ... --> comments flagging claims the models were uncertain about. An agent fetched the original source and confirmed the GPT 5.2 claims checked out, while the Opus generalizations were editorial inventions (correctly self-flagged by the model, at least). But the initial verification said "all claims check out," and that wasn't good enough.
I pushed back on a CVE reference. The draft cited CVE-2025-55284 as a current threat. A research agent confirmed the CVE was real (CVSS 7.5 HIGH, filed against claude-code), but also confirmed it was patched back in August 2025. That changed things. If the CVE was patched 7 months ago, writing about it like it's a current scare is editorially dishonest. This forced a complete reframe of the article's angle: from "here's why you need OS-level monitoring" to "OS-level agent security is becoming a product category." The CVE became a historical illustration of an architectural class of vulnerability, not a call to panic.
I pushed again: are our points even still relevant after seven months of security improvements? This triggered a comprehensive research pass covering current sandboxing in Claude Code, Cursor, and Codex; new security tools like NVIDIA OpenShell and Sysdig runtime detection; new CVEs that had landed since the original; and emerging industry standards from OWASP and NIST. The article's framing shifted again, from a single-tool pitch to an industry trend piece.
During final review, I clicked the OWASP link in the article. It was a download landing page with no visible numbered list. I asked the agent to confirm the specific rankings cited in the article. Two of the three OWASP numbers were wrong. A subsequent link audit caught two more fabricated details: the article claimed NVIDIA OpenShell used "kernel-level runtime using Linux Landlock LSM" (it's actually a containerized runtime with application-level policy enforcement), and it claimed Sysdig "announced at RSA" (the blog post doesn't mention RSA at all).
The final article shared almost nothing with the original drafts except a few of their best individual passages. Six rounds of verification. A bunch of factual corrections, even after the initial "verify" flags were sorted. A complete reframing of the editorial angle. That's one article.
This one started from two drafts about a research paper on coordination failure in multi-agent code generation. The verification was lighter; the VERIFY comments were mostly minor, and the paper's key numbers all checked out against the arxiv abstract.
The heavier editorial work was structural. I connected the paper's findings to two prior aeshift articles about spec difficulty and local context problems, naming a throughline that the AI hadn't identified on its own: "implicit knowledge resists codification." I asked about three spec-driven development tools (Kiro, Spec-kit, Tessl) as market context, which required three parallel research agents and turned up its own factual corrections. Kiro's pipeline phases were wrong in the draft. A claim about "early evaluations" of Spec-kit was actually a single evaluation. A funding claim about Tessl required a second source fetch to confirm.
After all the additions, the article had grown organically and had two disconnected "so what" sections. I restructured it into three acts with section headings, moving the recommendations from the middle (where the reader lacked context) to the end (where they land after understanding both the research and the market response).
The AI drafts were a useful starting point in both cases. But the editorial work that turned them into publishable articles took 60-90 minutes per piece, and that work was almost entirely human judgment: deciding what angle is editorially honest given the full context, catching factual errors the verification pipeline missed, connecting dots across prior coverage and larger industry landscape understanding, and restructuring to make the additions feel integral rather than bolted on.
A month in, a few patterns have emerged that I didn't expect.
The automated VERIFY comments do catch some unearned claims. Models flag things they're not sure about, and that's useful. But the verification pipeline consistently misses a category of error that's harder to detect: claims that are technically accurate but editorially misleading. A patched CVE is a real CVE. NVIDIA OpenShell does exist. The OWASP Top 10 for Agentic Applications is a real document. The verification step confirmed all of these as "accurate." The problem was that the surrounding claims about them (implementation details, announcement contexts, ranking numbers) were fabricated or wrong. The models don't flag confident assertions as needing verification, so the editor has to be the one clicking every link and questioning every specific detail.
This was the most consistent pattern across all 20 articles. Every time I said "dig deeper" or "is this actually true?" or "what's changed since then?", the result was either a factual correction or a reframing that produced a better article. The drafts are a starting point, not a destination. The editorial value comes from the iterative questioning, and that iteration is slow, manual, and requires domain expertise that the models don't have.
Both drafting models can summarize source material. GPT 5.2 seems to be ok at generating takes on individual topics. Neither one, across 20 articles, has spontaneously connected a new topic to prior coverage or identified a thematic pattern across sources. I have a refine-article skill which includes a prompt to examine recent articles and flag relevant connections. It's ok at doing this across the last few articles. But AI tools don't see the bigger picture beyond the data you point them at. This is the single biggest limitation for editorial content: the editorial lens is entirely human.
I was curious if one model would consistently outperform the other. That hasn't happened. GPT 5.2 tends to produce better-structured analytical pieces with stronger practitioner framing. Claude Opus tends to produce punchier openers and more provocative individual lines. The best articles have been hybrids: the structure and analysis from one draft, the hook and closing energy from the other. Having two drafts to compare also makes it easier to spot where each model is confabulating, because they rarely invent the same false details.
The pipeline is cheap to run. The editing is not cheap in terms of my time. Those 25-30 hours of editorial work across 20 articles average out to about 75-90 minutes per published piece. That's after the pipeline has already done the sourcing, scoring, drafting, fact-checking, and copy-editing. If I were writing these articles from scratch, it would probably be faster.
The pipeline's real value isn't saving me time. It's giving me an initial take on up to three high-topic-relevance articles. I don't have time to screen all the possible content pieces for a day, pick the best one, think about practitioner relevance angles - that's at least a half day of work. But I can say "out of these three content pieces, which one has the best practitioner relevance?" and work a draft into an article from it.
The copy-editing step catches the obvious ones: "fundamentally," "it's worth noting," "only time will tell." But the subtler tics require a human eye. Both models have a tendency to hedge with qualifiers that sound reasonable but drain the prose of conviction. They both overuse rhetorical questions. They both default to a conclusion structure that summarizes what they just said instead of landing on something new. I find myself making the same types of edits on every article, which means either the copy-editing prompt needs to be more aggressive or these patterns are too ingrained in the models to prompt away.
Twenty articles in, I can answer the questions I started with.
Can I convince AI to write useful content with minimal input from me? No. The input required is substantial; it's just a different kind of input than writing from scratch. Instead of staring at a blank page, I'm interrogating drafts, verifying claims, reframing angles, and restructuring articles. It's editing rather than writing, but it's not less work.
Can it provide a novel editorial take? Sometimes. The models produce serviceable takes that, with significant editorial shaping, become useful articles. But the novel connections, the thematic throughlines, the "this matters because of what we published last week" insights all come from me.
Can it produce accurate articles? Not without heavy verification. Every single article required factual corrections. Some were minor (wrong pipeline phase names, singular vs. plural). Some were serious (fabricated implementation details, wrong OWASP rankings, misleading CVE framing). The pipeline's verification step catches a small number of them. The rest require an editor who reads critically and clicks every link.
Can I edit out the AI writing tics? Mostly. The automated copy-editing pass handles the obvious markers. The subtler ones take manual work, and I'm still learning which tics I'm missing in my own editing passes.
I still think, for my needs, the pipeline is a useful tool for editorial content production. It's just not the "AI writes the blog" story that the stats at the top of this article might suggest. It's more like "AI produces a structured first draft that an experienced editor spends 90 minutes turning into something publishable." Whether that's worth it depends on what you value.
For me, spending time engaging deeply and thinking throgh the subject matter with the practitioner framing is the exercise. The output is just an artifact that I hope can be helpful to others. If you're hoping AI will let you publish editorial content without deep domain expertise and significant editorial investment, the current state of the art isn't there yet.
And this is one of the ways I know that organizations downsizing technical writing teams have a problem. If I spend up to 90 minutes editing and preparing a simple editorial article for publication daily, after a 7-step pipeline and with the aid of custom-crafted skills, there's no way that an AI content pipeline can write effective, error-free product documentation.
In which I build a system to filter AI-related content.
In which someone asks for something in 'skill-validator' and I spin up a new community research project.
In which a platform breaks the Agent Skills spec for its own benefit.


{kind=link}