

Vibes are Out, Data is In
In which I explain why a vibes-based approach to AI and docs ain't cutting it.
A month ago, I published an ecosystem-scale analysis of 673 Agent Skills from 41 repositories. I looked at Anthropic’s own skills, company-published collections from Microsoft and Stripe, community collections, and individual repos. The takeaway was that the ecosystem has real quality problems: 22% of skills fail structural validation, over half of all tokens are wasted on non-standard files, and broken links are everywhere.
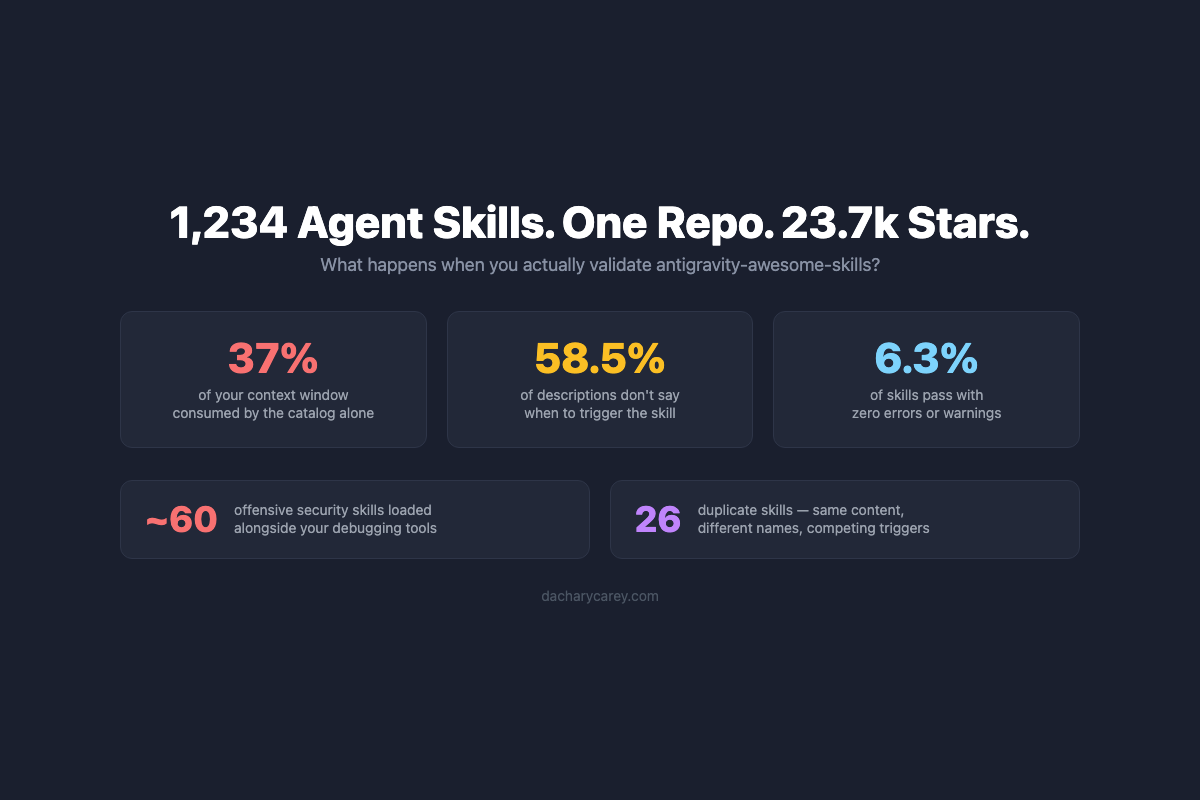
Today, I saw a post on LinkedIn about antigravity-awesome-skills, a single mega repo that claims over 1,200 Agent Skills and has 23.7k GitHub stars. That star count makes it one of the most popular skill sources in the ecosystem. People are presumably cloning this repo and loading these skills into their agents.
So I pointed my skill-validator at it and ran the full check suite across all 1,236 skills. But the most interesting findings aren’t about whether the skills are well-formed. They’re about what happens when you actually try to use a collection this large. You have two paths, and both have serious problems.
The default experience is bulk installation via npx antigravity-awesome-skills. The README describes it as a one-command setup. But loading 1,200+ skills into your agent has consequences that aren’t obvious until you understand how agents handle skills under the hood.
The Agent Skills specification recommends that platforms implement “progressive disclosure,” where agents load a catalog of every installed skill’s name and description at the start of every session. This is how the agent knows which skills exist without loading all their full contents upfront. The spec estimates 50-100 tokens per skill for this catalog entry.
I measured the actual catalog cost for this repo using tiktoken: the name and description fields across all 1,234 skills with parseable frontmatter average 38 tokens per skill, totaling 46,851 tokens. That’s 36.6% of a 128k context window, consumed before a single skill is activated and before the user types their first message.
Here’s the wild part: 38 tokens per skill is actually below the spec’s 50-100 estimate. The descriptions in this repo are often terse, keyword-stuffed, or missing trigger guidance, which keeps them short. If the descriptions were actually good (detailed, specific about when to trigger, properly disambiguated from neighboring skills), the per-skill average would be higher, and the total catalog cost would be worse. The repo is paying a 37% context tax for a catalog full of descriptions that don’t do their job well, and fixing the descriptions would make the tax even steeper.
For contrast, custom curating 5 well-known skills (systematic-debugging, test-driven-development, writing-skills, concise-planning, git-pushing) cost 126 tokens of catalog content total. At the spec’s 50-100 per-entry estimate, that’s 250-500 tokens, or roughly 0.2-0.4% of a 128k window.
The catalog cost is just the floor. When the agent activates a skill, it loads the full SKILL.md body. With the median skill at 1,728 tokens, activating 5 skills during a session adds another ~8,600 tokens. Combined with the catalog of 1,234 skills, that’s roughly 55,000 tokens of skill overhead, or 43% of a 128k context window, before the agent has read a single file from your project or processed a single line of your prompt.
That 47k-token catalog isn’t just expensive. It’s noisy. The description field is how agents decide which skill to activate for a given task, and at 1,200+ skills, the descriptions start stepping on each other.
I extracted all 1,234 descriptions and analyzed them for overlap. The problems are layered.
Topical pile-ups. Some domains have extreme skill density. I counted 84 skills whose names or descriptions mention security, 74 that mention documentation, 60 that mention React, and 47 that mention debugging. When a user says “create API documentation,” 20 skills are plausible matches. For “fix this security vulnerability,” 10 skills compete. The agent has to disambiguate based on description text that, in many cases, uses near-identical language.
Outright duplicates. I found 13 groups of skills (26 total) where the content is 85-100% identical. These aren’t skills imported from different upstream sources that happen to overlap. They’re internal copies created by the repo’s own organizational scheme. The naming pattern tells the story: code-refactoring-refactor-clean and codebase-cleanup-refactor-clean are the same skill filed under two category prefixes. code-review-ai-ai-review and performance-testing-review-ai-review are 100% identical, 453-line files; only the name field differs. Anthropic’s office suite skills (docx, pdf, pptx, xlsx) each appear twice, once under the original name and once with an -official suffix. All of these duplicate groups were introduced in a single v4.0.0 commit that added 550+ skills. An agent loading the full collection gets two copies of each, with identical descriptions, and no way to prefer one over the other.
No trigger guidance. Only 512 skills (41.5%) include any language about when to use them (“use when,” “use this for,” “triggers on”). The other 58.5% describe what the skill is without saying when it should activate. A description like “Comprehensive PDF manipulation toolkit for extracting text and tables” is useful for a human browsing a catalog but doesn’t tell an agent whether to activate for “convert this spreadsheet to PDF” vs. “extract the table from page 3.”
Wrong field, wrong purpose. 97 skills (7.8%) use their description as a comma-separated keyword list, treating it like SEO metadata. Another 41 use it as a system prompt, starting with “You are a…” An agent scanning 1,200 descriptions to decide which skill to trigger doesn’t need to know “you are an expert”; it needs to know what task this skill handles.
These aren’t problems at small scale. An agent loading 5 hand-picked skills is unlikely to hit trigger conflicts. An agent loading 1,200 is almost guaranteed to.
Beyond context pressure and trigger ambiguity, there’s the question of what’s in the collection. Loading 1,200+ skills indiscriminately means you’re trusting that every skill is appropriate for your use case, and that turns out to be a significant assumption.
The repo contains roughly 60 offensive security skills. active-directory-attacks teaches Kerberoasting, DCSync, pass-the-hash, Golden Ticket attacks, and credential extraction with Mimikatz. linux-privilege-escalation walks through kernel exploits, SUID abuse, and cron job hijacking. sql-injection-testing covers in-band, blind, and out-of-band SQLi techniques with SQLMap. metasploit-framework is a 487-line guide to exploitation, payload generation, credential harvesting, keylogging, and AV evasion. These are legitimate pentesting skills; security professionals use these techniques every day. But most people installing a “curated skills collection” for their coding agent aren’t expecting to hand it a Metasploit tutorial. The repo’s own recommended “Tier S” skills list focuses on debugging, TDD, and documentation, not offensive security tooling.
The repo does add a non-spec risk field to skill frontmatter, but it doesn’t help. 797 skills are labeled unknown, 237 are safe, and only 1 of the ~60 security skills is labeled offensive. The rest carry risk: unknown. An agent can’t use that to make any meaningful decision.
The repo’s README acknowledges this isn’t an all-or-nothing proposition. It offers curated “bundles” organized by role (Web Wizard, Security Engineer, OSS Maintainer) and even includes a web app for browsing the catalog. But the tooling for choosing doesn’t match the scale of the collection.
The web app shows each skill as a card: the name, a three-line description preview (CSS line-clamp-3), a category tag, and a community star count. You can search by name or description text, filter by category, and sort by stars, date added, or alphabetically.
The human gets roughly the same information that the agent gets from the catalog, and it has the same problems. There’s no token count, so you can’t tell whether a skill is 500 tokens or 300,000. There’s no content quality indicator. There’s no information about whether a skill’s description overlaps with others you’ve already selected. The detail page renders the full SKILL.md, but at that point you’re reading each skill individually, which is exactly the scale problem the web app was supposed to solve.
A user trying to pick 5 good skills from 1,200 is essentially browsing an app store where every listing has the same amount of information as a tweet. And as we saw, 58.5% of those tweets don’t even explain when the skill should trigger.
Even if you’re willing to read skills individually, you can’t easily tell where they came from. I extracted the source field from the 1,056 of 1,234 skills that have one (178 skills have no source field at all):
| Source Label | Skills | What it means |
|---|---|---|
community |
859 | Generic label, no specific origin |
vibeship-spawner-skills |
54 | Batch-imported from a skills generator |
self / personal / original |
72 | Claimed as original content |
| GitHub URL | 63 | Links to a specific external repo |
| Other | 8 | Miscellaneous labels |
The git history confirms systematic importing: “feat: integrate official Anthropic and Vercel Labs skills,” “feat: Add 57 skills from vibeship-spawner-skills,” “feat: sync all 140 Microsoft skills with collision protection.” The repo even has a dedicated sync_microsoft_skills.py script that shallow-clones Microsoft’s skills repo and copies everything over.
But the 859 skills labeled community obscure where they actually came from. I found Anthropic’s own skills (canvas-design, doc-coauthoring, docx, pdf, pptx, skill-creator, writing-skills, xlsx) all labeled source: community. obra/superpowers skills like systematic-debugging, test-driven-development, and verification-before-completion, the standout performers in my ecosystem analysis, also carry the generic community label.
To be fair, the repo’s README does include a Credits & Sources section and a more detailed Attribution Ledger that credit Anthropic, obra/superpowers, Trail of Bits, Expo, Hugging Face, Sentry, and many others. The README-level attribution is genuinely thorough. But this creates a two-layer problem: the credit exists in a document a human might read, while the skill files themselves carry no link to their origin. If you’re evaluating whether to trust a skill, the frontmatter tells you nothing.
This matters beyond attribution. When a skill is copied into a mega collection, it becomes a frozen snapshot. If the original author fixes a bug, closes an unclosed code fence, or updates their content, the copy doesn’t get those fixes. The 859 community skills have no sync pipeline back to their upstream sources. If you want systematic-debugging, you’ll get a better experience pulling it from obra/superpowers directly.
I ran the full skill-validator check suite (structure, content analysis, and contamination analysis, minus link validation) across all 1,236 skills. The structural numbers provide useful context for the DX problems above.
96.3% pass structural validation (1,190 of 1,236), but only 6.3% are fully clean (78 skills with zero errors and zero warnings). The high pass rate comes from a consistent template that gets the basics right: correct directory structure, valid frontmatter, proper naming. But the template also adds three non-spec fields (source, risk, date_added) to every skill, producing 3,476 of the 4,528 total warnings. A single template decision propagated across 1,200+ skills is a different kind of quality problem than individual authors making individual mistakes.
Unclosed code fences are the dominant failure mode: 26 of the 46 failing skills have a code fence that opens but never closes. The skill loads without any obvious error, but the agent treats everything after the unclosed fence as a code block. All instructions after that point become invisible. The author likely never noticed because GitHub’s Markdown preview is more forgiving than a strict parser.
The token long tail is steep. The median skill is 1,728 tokens, which is reasonable. But 7 skills exceed 50,000 tokens, and several exceed 300,000. The worst offender, loki-mode, bundles 1.5 million tokens of non-standard content (an API server, dashboard, Docker config, VS Code extension) alongside just 5,200 tokens of actual skill instructions.
My earlier analysis covered 673 skills from 41 repositories, with a 22% failure rate. The mega repo’s 3.7% failure rate looks better, but the two datasets aren’t directly comparable. The ecosystem analysis covered diverse sources with different authoring approaches; the mega repo’s uniform template prevents many individual-author errors while introducing its own systemic issues at scale.
The content quality metrics tell a more nuanced story:
| Metric | Mega repo (1,234 skills) | Ecosystem (673 skills) |
|---|---|---|
| Median word count | 886 | ~1,200 |
| Mean code block ratio | 0.23 | ~0.30 |
| Mean imperative ratio | 0.14 | ~0.16 |
| Mean information density | 0.21 | ~0.24 |
| Zero code blocks | 31.3% | ~20% |
| Low imperative ratio (<0.05) | 21.3% | ~15% |
| Low information density (<0.10) | 22.8% | ~18% |
The mega repo’s skills are shorter, contain less code, give fewer direct instructions, and pack less information per sentence than the ecosystem average. Nearly a third have no code blocks at all. Over a fifth have such low imperative ratios that they read more like descriptions than instructions.
Cross-language contamination levels are similar between the two datasets (~1.5% high, ~25% medium), but the absolute numbers are larger in the mega repo: 332 medium-risk and 18 high-risk skills. In the ecosystem analysis, I found that contamination scores don’t reliably predict behavioral degradation, but contamination does increase the surface area for problems.
One pattern holds across both analyses: skills that try to do too much fail the hardest. loki-mode (1.5M tokens of non-standard content) is the same kind of problem as oversized reference bundles in the ecosystem. A skill should be lean, focused context augmentation. When it becomes a vehicle for shipping an entire codebase, the format breaks down.
The fundamental problem with a mega repo isn’t that the skills are poorly made (most pass structural validation) or that the collection is assembled carelessly (the attribution is genuinely thorough). The problem is that the format creates a dilemma with no good exit.
If you load everything, you pay 37% of your context window in catalog overhead, face trigger ambiguity across dozens of overlapping domains, and silently load offensive security content alongside your debugging and documentation skills. If you try to be selective, the browsing tools give you a name, a three-line description, and a star count. No token costs, no quality metrics, no overlap warnings, no provenance in the skill files themselves.
Here’s what I’d recommend instead.
Go to the source. Many of the best skills in this repo are copies from their original repositories: Anthropic’s official skills, obra/superpowers, Trail of Bits, Expo, Hugging Face, Sentry. Those originals get bug fixes and updates. The copies here are frozen snapshots with no upstream sync.
Keep your collection small. Five well-chosen skills cost ~125 tokens of catalog content, or 250-500 with platform framing. 1,200 cost 47,000 before framing. Beyond the raw token math, smaller collections avoid trigger ambiguity entirely. Your agent doesn’t need to disambiguate between 20 documentation skills if you’ve only installed the one you actually want.
Validate what you use. Run the skill-validator on anything you plan to load. The unclosed code fence problem is especially insidious because the skill looks fine in a Markdown preview but silently fails when an agent tries to parse it.
Know what you’re loading. Read the SKILL.md before you install it. If you wouldn’t give a junior developer unsupervised access to Metasploit, SQL injection tooling, and Active Directory exploitation techniques, think about whether you want those loaded as context in your coding agent.
I found this repo through a LinkedIn post that framed it as a must-have: “AI agents are powerful, but they lack specific tools and knowledge.” One npx command, 1,250+ skills, save and repost. That post takes 30 seconds to read. It doesn’t mention that installing the collection costs 37% of your context window before you type a word, that 20 skills will compete to handle your next documentation request, that you’re loading Metasploit tutorials alongside your debugging tools, or that many of the best skills are frozen copies you could get fresher from the original authors.
None of that is visible from the outside. You have to actually measure it. And that’s the real problem with the AI influencer ecosystem around tooling like this: the signal that travels fastest (“1,250 skills! one command!”) is the signal that requires the least scrutiny. The information you actually need to make a good decision (token costs, description quality, content provenance, trigger overlap) takes an hour of digging on a weeknight with the right tools. Most people won’t do that digging. They’ll run the npx command, notice their agent feels slower or picks the wrong skill sometimes, and never connect it back to the 1,200 skills they installed because a LinkedIn post told them to.
The question isn’t “how many skills can I install?” It’s “which skills actually make my agent better at the work I’m doing?” The answer to that question is almost never 1,200.
In which I explain why a vibes-based approach to AI and docs ain't cutting it.
In which I lurk in server logs and try to make sense of what I see.
In which I talk about what's inside a coding agent.


{kind=link}