
Agent Skill Mega Repo Woes
In which I validate a 23.7k-star skill mega repo and discover problems the star count won't tell you.
Experienced documentation writers know that grammar isn't the only important aspect of documentation. Readability is a huge part of what makes documentation good. Readable documentation:
The Nielsen Norman Group advises writers target an 8th grade reading level. Most technical writing comes in at 12th grade or higher. Documentarians sometimes use the excuse that it's "technical writing" so higher is ok. This doesn't consider that the density of documentation is an accessibility issue.
Who needs simple documentation?
Even if you aren't targeting an international audience, simple documentation benefits everyone. But it might surprise you to know that the average American has a 7th to 8th grade reading level. Some sources estimate it's even lower than that. So if you write to an 8th grade level, you're writing for the average American.
Improving docs readability has been a pet project of mine for a while. But I've had mixed success getting my teammates to care about readability. So for hackathon, I decided to automate readability scoring for our documentation.
There was one complication: we write our documentation in reStructuredText. The readability scoring libraries that are currently available score markdown or plain text. So I needed to be able to parse our rST to plain text.
Enter docdoctor. Docdoctor is a tool that my lead, Chris Bush, wrote. It's a TypeScript/ Node command line tool to manipulate rST files in our docs repositories. It uses another library, restructured, to parse the reStructuredText. It adds some tools on top to deal with some things that are specific to our docs toolchain.
I added a command to this command-line tool to manipulate the rST to output plain text. Along the way, I make some tweaks to improve the accuracy of readability scoring. There's a fair amount of markup that skews the readability scores. We really only want to be scoring the content for readability. So I throw out a lot of markup, and add punctuation in places, to focus scoring on the content.
After converting the rST to plain text, with a few minor tweaks, we can score it for readability. We're using a Python library, textstat, to do the scoring. This library lets you select from 16 readability heuristics. I've chosen two: Flesch-Kincaid Grade Level and Flesch Reading Ease.
The automation that I've set up applies these heuristics to every file in a documentation PR. This gives us readability scores for everything we touch while we work.
With these tools, I can automate scoring our documentation PRs for readability. I've set up two GitHub workflows that automate this process.
The first workflow:
It stores the output of our textstat scoring script as a workflow artifact.
The second workflow:
The second workflow is separate for security reasons. If the first workflow actually posted the comment, it could expose the GitHub token to bad actors. (Don't ask me how I know this.)
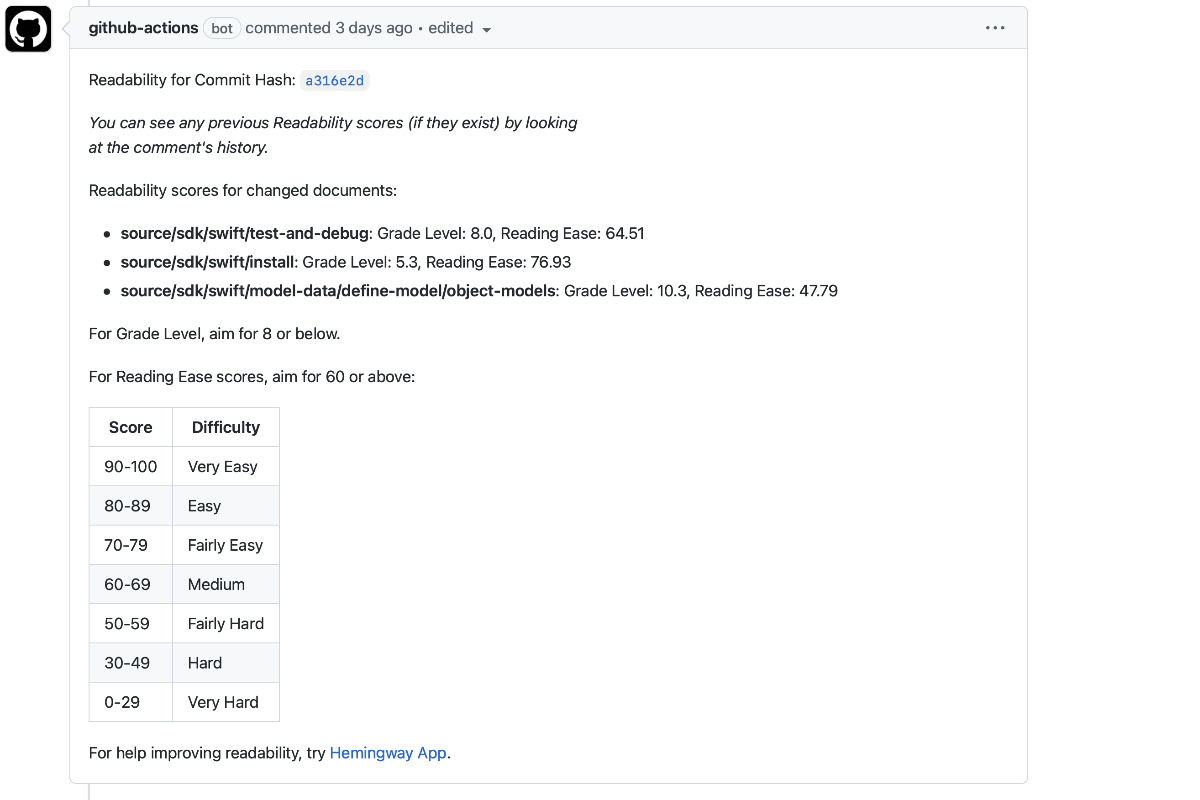
The end result is this: for every docs PR, we get a comment posted on the PR with readability scores for each file we touch.

It provides recommended readability score targets. And a link to Hemingway App so writers can get tips to improve readability.
Providing docs writers feedback about readability on every PR makes readability visible. If you see that chart saying "Oh, it's fairly hard to read this page" you may think about improving that. My hope is that this will lead to more work improving readability docs-wide. At the very least, it will remind me to go refactor my docs pages for readability.
In which I validate a 23.7k-star skill mega repo and discover problems the star count won't tell you.
In which I show you how I made multiple Hugo sites agent-friendly.
In which I deep dive on a Stripe Skill, and what it means for the industry.


{kind=link}