

How to Evaluate a Platform-Written Spec
In which I find that a platform-published spec's omissions track financial incentives.
Claude introduced Agent Skills in fall 2025, and they have quickly become the next hot thing in AI-assisted development. Agent Skills give your AI buddy just-in-time context to help it succeed with tasks that require specific domain expertise or resources. Anthropic released an Agent Skills specification, and other agentic platforms have been rushing to add support for it. In turn, individual developers are making their own Agent Skills, and companies are under pressure to provide official Agent Skills for customers to use in agentic development workflows.
Any given Agent Skill must hit two targets to actually achieve the promise of improving LLM outputs:
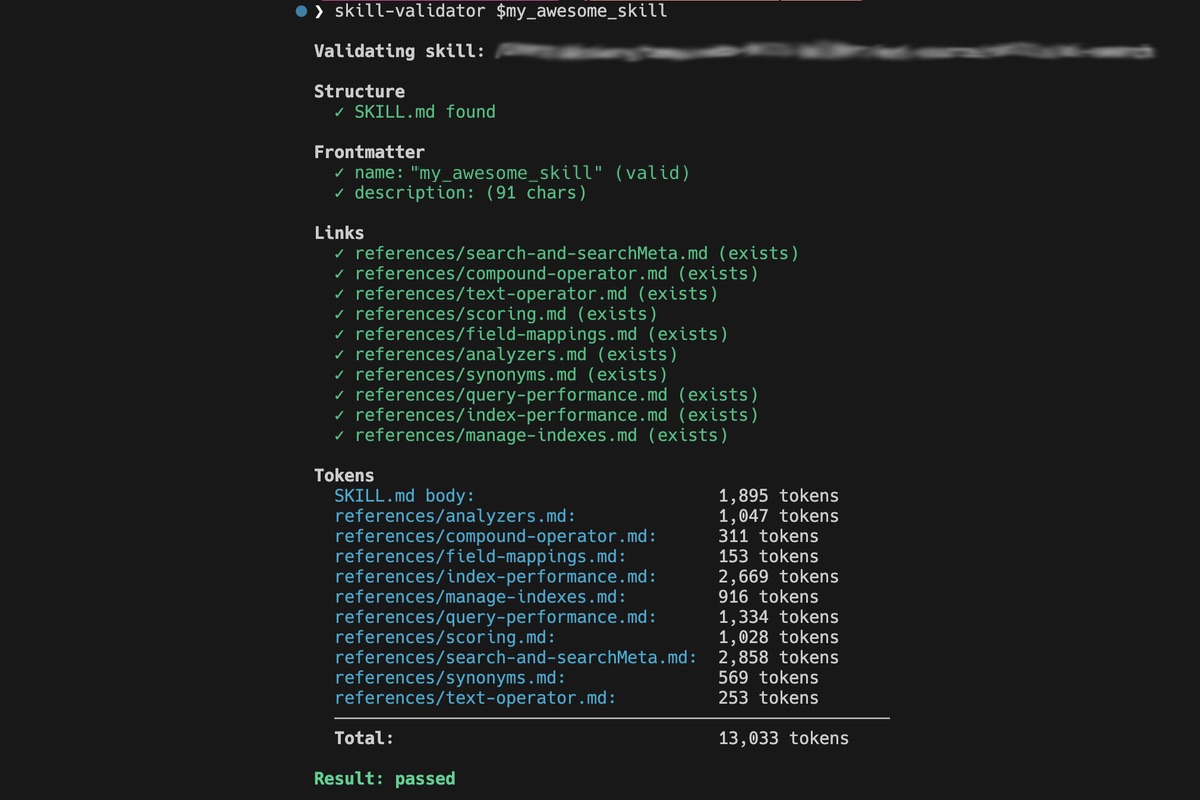
I've been seeing a proliferation of Agent Skills that miss on one or both of these requirements, so I wrote a Skill validator and performed some analysis to dig deeper into how widespread this issue is. Here's an informal summary of my findings; I'm planning to put together a more detailed report for folks who really want to dig into the data.
A specification is an engineering tool. It represents a shared agreement of how something should function, and gives developers something to code and validate against. This means it's not just a recommendation; agent platforms that build support for Agent Skills implement the specification.
If your Agent Skill content does not match the specification, agent platforms may not be able to use it. If it's close, agent platforms may be able to use parts of it, but some types of spec noncompliance may prevent agent platforms from using your Agent Skills entirely.
Anthropic released its own reference library implementation to demonstrate how people might implement validators.
My skill validator implementation performs these same checks. This is the minimum cost of entry for any Agent Skill.
scripts/, references/, assets/); no deep nesting.name, description) are present and valid; name is lowercase alphanumeric with hyphens (1-64 chars) and matches the directory name; optional fields (license, compatibility, metadata, allowed-tools) conform to expected types and lengths; unrecognized fields are flaggedAfter performing some analysis, I was surprised by how many Agent Skills do not comply with this spec - including 3 of Anthropic's own 16 published Agent Skills. More on that in a minute.
This is where my skill validator goes beyond the spec and gets opinionated. The point of an Agent Skill is to provide lean, just-in-time context augmentation to help LLMs produce better outputs. There are entire classes of issues where an Agent Skill may technically comply with the spec, but produce worse outputs because of these issues. If an agent wastes context on broken links, irrelevant files, or oversized references, this pollutes the agent context window and causes the agent to produce worse outputs - the opposite outcome to the objective of Agent Skills.
To help flag these issues, my skill validator reports warnings and errors for:
You can get more details about how these issues can affect agent outputs and why I flag them in the README for my tool.
For the purposes of reporting on this analysis, I flag most of these issues as warnings, because they can degrade the LLM performance when using your Agent Skills but don't actually prevent the LLM from using the Skills. But I report the holistic structure check and token counting hard limits as errors, since these will prevent agent platforms from using your Agent Skills.
For a quick analysis, I looked at two sources of Agent Skills:
I followed up with a deeper analysis that looked at Skills from more sources, including official company-promoted Skills. You can view the interactive dashboard or download the paper at Agent Skill Analysis - Interactive Report.
Anthropic publishes 16 Agent Skills in their official skills repository. Since they wrote the spec, I expected these to be exemplary implementations. Instead, my validator reported 8 errors and 39 warnings, and 3 of the 16 skills failed validation entirely.
skill-creator had the most errors by far, with 6 broken internal links. Its SKILL.md references files like FORMS.md, REFERENCE.md, EXAMPLES.md, DOCX-JS.md, REDLINING.md, and OOXML.md - none of which exist in the skill directory. When an agent follows these links and finds nothing, it wastes cycles on dead ends — and the skill's own guidance is incomplete, since whatever those files were supposed to contain is simply missing. This is especially ironic because the skill-creator skill is supposed to teach agents how to build other skills correctly.
canvas-design failed the holistic structure check. It bundles a canvas-fonts/ directory containing 81 files — 54 .ttf font files and 27 OFL (Open Font License) text files. The SKILL.md explicitly instructs agents to "Search the ./canvas-fonts directory" for fonts to use, so the font files are there for a reason: they're legitimate assets the skill needs. The problem is the packaging. The .ttf binaries are skipped by the tokenizer (0 tokens), but the 28 license text files (27 OFL files inside canvas-fonts/ plus the root LICENSE.txt) total 26,657 tokens against only 2,281 tokens in the actual skill body — a roughly 12:1 ratio of legal boilerplate to useful content. Simply renaming canvas-fonts/ to assets/canvas-fonts/ would fix the validation, since assets/ is a recognized directory in the spec. But even then, when an agent follows the SKILL.md instruction to search the fonts directory, it may load those license files into context. The font files have a reason to be here; the license files are a legal requirement of the OFL. This is a case where the skill has a legitimate need that runs up against the token-efficiency goals of the spec.
doc-coauthoring references https://claude.ai in its SKILL.md, which returns an HTTP 403 to automated requests. This may be a false positive — claude.ai likely blocks the kind of HEAD requests the validator uses while being accessible to Claude itself. But it highlights a real tension in link validation: an agent encountering a link it can't follow has to either skip it or waste cycles attempting access, and the skill author has no way to know which links will be accessible in which agent environments.
The 39 warnings fell into three categories:
Extraneous files (32 structure warnings): Every single one of Anthropic's skills that ships with a LICENSE.txt (15 of 16) gets flagged, because license files aren't part of the spec's recognized structure. A well-implemented agent following progressive disclosure would only load files referenced by the SKILL.md, so the practical risk depends on the platform — but any agent that scans the skill directory broadly could end up loading license text instead of task-relevant content. Beyond license files, several skills use non-standard directory names (templates/, canvas-fonts/, examples/, reference/, core/, themes/) instead of the spec's recognized directories (scripts/, references/, assets/). Agents that follow the spec's standard structure won't discover files in these directories. Other skills place reference files at the skill root (forms.md, reference.md, editing.md, pptxgenjs.md) instead of inside a references/ directory where agents expect to find them. Three skills (docx, pptx, xlsx) have deep nesting inside scripts/office/, which agents may not traverse.
Keyword-stuffed descriptions (6 frontmatter warnings): Six skills (docx, frontend-design, internal-comms, pdf, pptx, xlsx) use their description field as a keyword list rather than a concise explanation. For example, the pptx skill has 20 comma-separated segments in its description. The description is the primary mechanism for an agent to decide whether to activate a skill — it should concisely describe what the skill does and when to use it. Keyword stuffing this field treats it like SEO metadata rather than useful context for the agent.
Token bloat (1 token warning): The canvas-design skill's 26,657 tokens of non-standard content got a specific token warning before it tripped the holistic check that failed it outright.
If the people who wrote the Agent Skills spec can't get their own skills to pass validation, it signals a gap between the spec as written and the spec as practiced. These aren't esoteric edge cases - broken links, non-standard directories, and extraneous files are fundamental issues that directly impact how well agents can use the skills.
The Awesome Claude Skills repo showcases 11 community skill repositories. I cloned all of them and ran my validator across every skill I could find. Some repos contain a single skill; others are collections. In total, I analyzed 218 skills from these sources:
| Source | Skills | Passed | Failed |
|---|---|---|---|
| K-Dense-AI/claude-scientific-skills | 141 | 101 | 40 |
| trailofbits/skills | 52 | 28 | 24 |
| obra/superpowers | 14 | 14 | 0 |
| obra/superpowers-lab | 4 | 3 | 1 |
| obra/superpowers-skills | 1 | 0 | 1 |
| 6 individual skill repos | 6 | 1 | 5 |
| Total | 218 | 147 (67%) | 71 (33%) |
Across all 218 skills, the validator reported 128 errors and 252 warnings.
allowed-tools Type AmbiguityBefore digging in, I need to flag an important finding. 33 of the 71 failures — 20 from K-Dense and 13 from Trail of Bits — are caused by the same issue: these skills declare allowed-tools as a YAML list (e.g. allowed-tools: [Read, Write, Bash] or as an expanded YAML sequence), but my validator types that field as a string. When the YAML parser hits a list where it expects a string, it fails immediately and can't validate anything else about the skill.
This is an open question about the spec. The Agent Skills specification defines allowed-tools but is ambiguous about whether it should be a string or a list. In practice, a list makes more semantic sense (it is a list of tools), and both Trail of Bits and K-Dense independently chose to implement it that way. This is worth noting as a spec ambiguity that the ecosystem is interpreting inconsistently. For the rest of this analysis, I'll separate these YAML parse failures from the "real" quality issues.
The standout performer was obra/superpowers, a collection of 14 skills for Claude Code workflows like TDD, debugging, and code review. Every single skill passed validation with zero errors. There were 22 warnings (mostly around file placement), but nothing that would degrade agent performance.
What makes superpowers work? The skills are lean and focused. The median SKILL.md body across the collection stays well under the 5,000-token guideline. Each skill does one thing — "systematic-debugging," "test-driven-development," "verification-before-completion" — and provides just enough context for the agent to execute that workflow. This is what the spec's progressive disclosure architecture is designed for.
The K-Dense-AI scientific skills collection is the largest single source at 141 skills, covering everything from alphafold-database to zinc-database. It's an ambitious attempt to give agents expertise across dozens of scientific libraries and databases.
But the collection shows clear signs of automated generation at the expense of quality:
Keyword-stuffed descriptions: 32 of 141 skills (23%) use their description field as a keyword list. For example, geopandas has 18 comma-separated segments and lamindb has 22. The description field is how agents decide whether to activate a skill — stuffing it with keywords may increase false-positive activations, where the agent loads the skill for tasks where it's not actually helpful, wasting context tokens.
Token-heavy bodies: 14 skills exceed the 5,000-token SKILL.md body guideline. The heaviest, imaging-data-commons, clocks in at 10,076 tokens in the body alone. Many skills pile additional content into references/ directories, pushing total token counts above 25,000. The top offender, neurokit2, totals 44,979 tokens in standard structure content. When an agent activates one of these skills, it consumes a substantial fraction of the context window before the user's actual task gets any attention.
Broken links: 36 link errors across the collection. Some of these are unambiguous — the neuropixels-analysis skill references three files in reference/ (standard_workflow.md, api_reference.md, plotting_guide.md) that simply don't exist. But a fair number are HTTP 403 errors from DOI resolvers and academic publishers (doi.org, science.org, mathworks.com) that block automated HEAD requests while working fine in a browser. These are likely false positives from my validator, not genuinely broken links. The remaining errors — API endpoints returning 404, authentication-gated URLs — are more clearly problematic.
Trail of Bits publishes 52 skills primarily focused on security — static analysis, fuzzing, vulnerability detection, and code auditing — along with some general developer productivity skills. The quality is generally higher than the scientific collection, but the repo still has issues.
The biggest problem is the allowed-tools YAML type issue: 13 skills fail parsing entirely because of it. Beyond that, 11 more skills fail for broken links — some referencing internal files that don't exist (property-based-testing references 7 missing files in {baseDir}/references/), others linking to external URLs that return errors.
The structural organization is also non-standard. Trail of Bits nests their skills inside plugins/*/skills/*/, which adds discovery complexity. Within the skills themselves, 12 use resources/ instead of the spec's references/ directory, meaning agents following the standard structure won't find the supporting content.
Of the 6 individual skill repos listed in the Awesome Claude Skills community section, only 1 passed validation (ios-simulator-skill). The other 5 failed:
ffuf-web-fuzzing had 17 errors — almost entirely broken links. The SKILL.md is full of example URLs like https://target.com/FUZZ and http://127.0.0.1:8080 that are meant to be illustrative but show up as dead links. The skill also has a name mismatch: the frontmatter says ffuf-web-fuzzing but the directory is named ffuf-skill.
claudeskill-loki-mode is the most extreme case in this entire analysis. It describes itself as a "multi-agent autonomous startup system" that "orchestrates 37 AI agents across 6 swarms." The repo is 24MB and contains 2,979,492 tokens of non-standard content — including an API server, a dashboard, Docker configuration, a VS Code extension, a wiki, and more. It has a SKILL.md at the root, but this is an entire software platform, not a skill. The 42:1 ratio of non-standard to standard content makes it clear this doesn't belong in the Agent Skills format.
playwright-skill and web-asset-generator both fail on broken links. claude-d3js-skill fails because its frontmatter name (d3-viz) doesn't match the directory name (claude-d3js-skill) — a simple fix, but one that could prevent agent platforms from discovering the skill.
Across all 218 community skills, the issues cluster into a few recurring patterns:
Broken links are the #1 error (85 total). These split into three types: placeholder/example URLs that were never meant to resolve (22), HTTP links that return errors (30), and internal references to files that don't exist (33). A caveat: some of the HTTP errors are likely false positives — academic publishers and DOI resolvers often block automated HEAD requests while working fine in a browser. The missing internal files and placeholder URLs, however, are unambiguous problems. When a skill references a file that doesn't exist, the agent loses access to content the skill author intended to provide.
Structural non-compliance is pervasive. 54 skills use non-standard directory names, 46 place files at the skill root instead of in recognized directories, and another 13 have deep nesting or repo-level files bundled into the skill. This means agents that follow the spec's directory conventions won't discover the content these skills are trying to provide.
Keyword stuffing is systematic (40 warnings). Primarily concentrated in the K-Dense collection, but also present in other skills. This pattern treats the description field like SEO metadata rather than a useful trigger for agent activation.
Token budgets are routinely exceeded. Of the 185 skills that could be fully analyzed (33 failed YAML parsing before token counting), 122 (66%) exceed 5,000 total tokens in their standard structure. The median SKILL.md body is 2,725 tokens, which is reasonable, but the long tail is severe — several skills push past 25,000 tokens, and the loki-mode outlier hits 70,000 in standard structure alone (plus 3 million in non-standard content).
Across 234 skills from Anthropic and the community, the same issues come up over and over. If you're building or distributing Agent Skills, here's what the data says matters.
Validate before you publish. The most common errors — broken links, name mismatches, missing files — are all caught by basic automated checks. Run a validator as part of your workflow, not as an afterthought. My skill-validator is one option; Anthropic's reference implementation is another. The specific tool matters less than having any validation in your pipeline.
One skill, one job. The cleanest collection in this analysis was obra/superpowers: 14 skills, zero errors, each focused on a single workflow. The worst performers tried to do too much — cramming entire platforms, exhaustive API references, or dozens of library guides into a single skill. A skill that tries to cover everything ends up consuming a huge chunk of the context window before the agent even starts working on the user's task. If your skill exceeds 5,000 tokens in the body, ask whether it's really one skill or several.
Write descriptions for agents, not search engines. The description field is how agents decide whether to activate your skill. Stuffing it with comma-separated keywords — a pattern I saw in 46 skills across this analysis — treats it like SEO metadata. For example, the lamindb skill's description contains 22 comma-separated segments: "scRNA-seq, spatial, flow cytometry, etc.), tracking computational workflows, curating and validating data with biological ontologies, building data lakehouses..." An agent needs a clear sentence about what the skill does and when to use it, not a keyword dump.
Use the spec's directory structure. references/, scripts/, and assets/ exist because agent platforms implement discovery based on these conventions. When you put files in resources/, examples/, core/, or templates/, agents following the spec won't find them. Structural issues were the most common warning category across this analysis — 54 skills used non-standard directories, and 46 placed files at the root where they don't belong.
Test your links. Broken links were the #1 error across the entire analysis. Links rot, files get renamed, APIs change. If your SKILL.md references internal files, make sure they exist. If it includes URLs, check that they resolve. This is doubly important for example URLs in instructional content — placeholder domains like target.com and example.com will show up as broken links to any agent that tries to follow them.
Know what a skill is — and isn't. A skill is lean, just-in-time context augmentation. It is not a full application, a documentation dump, or an entire codebase with a SKILL.md dropped in the root. If your repo has a Docker configuration, a VS Code extension, and a wiki alongside your SKILL.md, it's not a skill — it's a project that happens to have a skill manifest.
In which I find that a platform-published spec's omissions track financial incentives.
In which I use AI to help draft content, and discover its limitations.
In which I build a system to filter AI-related content.


{kind=link}