

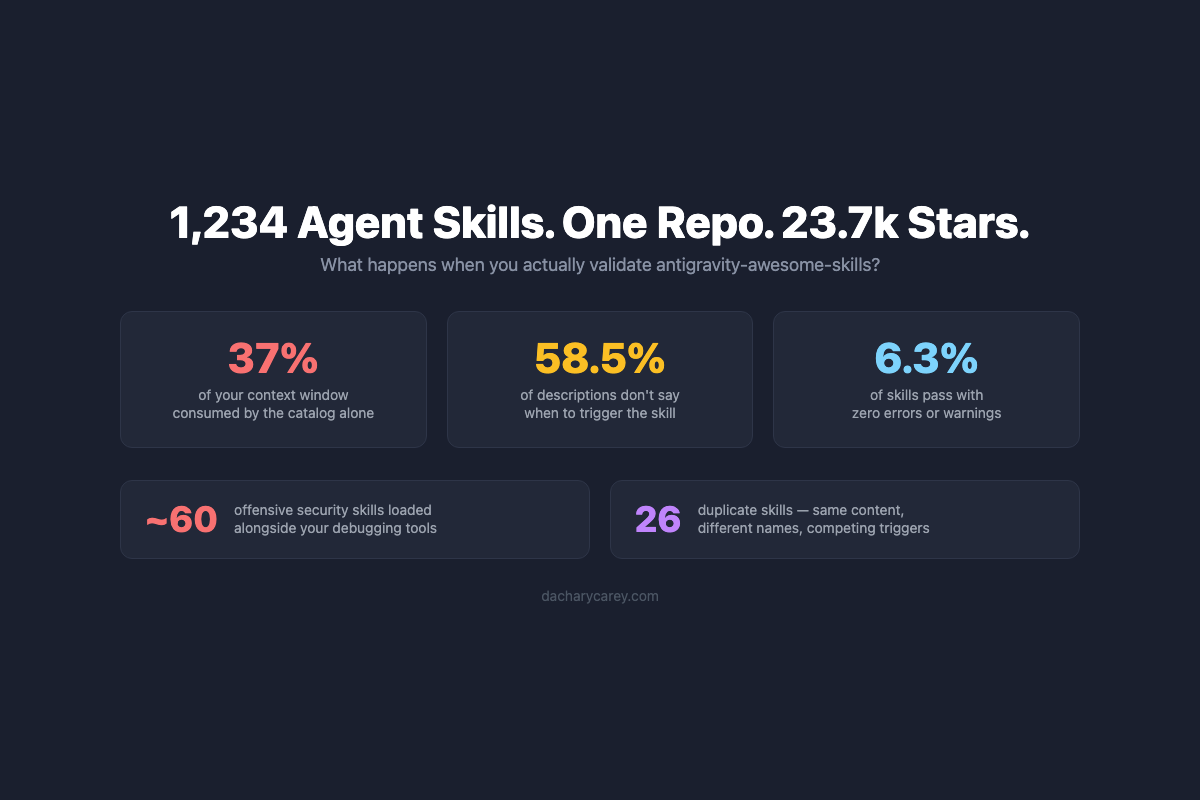
Agent Skill Mega Repo Woes
In which I validate a 23.7k-star skill mega repo and discover problems the star count won't tell you.
As we worked our way through this initial code example audit process, requirements emerged sporadically. At the core of this project, our department wanted to understand our code example content distribution and communicate about it to leadership. That became "count the code examples" by category and programming language. Even as we iterated on the tooling to perform the initial count, new requirements emerged. My team agreed that we couldn't just take a static "count" approach - we needed to store information about our code examples in a database, so we could slice the data in whatever new way leadership wanted to break it down.
So what information did we need to store, and how should we organize it?
Nobody told us what information to store. We didn't get a clear set of requirements before starting the project - mainly because nobody had undertaken something on this scale in our organization, and we didn't really know what was possible or feasible. So I took my favorite approach - figure it out by building something.
This is exactly the type of project where the flexible document model shines. MongoDB can store data in whatever form you want. No tables, joins, or clunky migrations if you change your mind about how you want to deal with the data. So we didn't have to have a full specification before we could model the data. I could - and did - change the data model along the way as new requirements emerged. MongoDB also gives us the luxury of storing different types of data in the same collection. So my team created two document models to provide relevant information about the code examples:
The audit summary gives us a high-level snapshot of the documentation project each time we run the audit. We can look at the history of this document to find out:
type CollectionReport struct {
ID string `bson:"_id" json:"_id"`
Version map[string]CollectionInfoView `bson:"version" json:"version"`
}
type CollectionInfoView struct {
TotalPageCount int `bson:"total_page_count" json:"total_page_count"`
TotalCodeCount int `bson:"total_code_count" json:"total_code_count"`
LastUpdatedAtUTC time.Time `bson:"last_updated_at_utc" json:"last_updated_at_utc"`
}
In practice, one of these documents may resemble:
{
"_id": "summaries",
"version": {
"v6.15": {
"total_page_count": 94,
"total_code_count": 532,
"last_updated_at_utc": 2025-04-03T03:58:53.955+00:00
},
"v6.13": {
"total_page_count": 94,
"total_code_count": 516,
"last_updated_at_utc": 2025-02-21T02:49:52.764+00:00
}
}
}
As you can see, this particular collection had snapshots for two docs versions - v6.15 and v6.13. The page count remained static between versions, but the v6.15 version had more code examples than the older version.
The page document stores information about each page in a documentation set, and all the code examples on that page. We can look at this document to find out:
literalincludes and io-code-block)type DocsPage struct {
ID string `bson:"_id"`
CodeNodesTotal int `bson:"code_nodes_total"`
DateAdded time.Time `bson:"date_added"`
DateLastUpdated time.Time `bson:"date_last_updated"`
IoCodeBlocksTotal int `bson:"io_code_blocks_total"`
Languages LanguagesArray `bson:"languages"`
LiteralIncludesTotal int `bson:"literal_includes_total"`
Nodes *[]CodeNode `bson:"nodes"`
PageURL string `bson:"page_url"`
ProjectName string `bson:"project_name"`
Product string `bson:"product"`
SubProduct string `bson:"sub_product,omitempty"`
Keywords []string `bson:"keywords,omitempty"`
DateRemoved time.Time `bson:"date_removed,omitempty"`
IsRemoved bool `bson:"is_removed,omitempty"`
}
// CodeNode captures metadata about a specific code example. The `Code` field contains the example itself.
type CodeNode struct {
Code string `bson:"code"`
Language string `bson:"language"`
FileExtension string `bson:"file_extension"`
Category string `bson:"category"`
SHA256Hash string `bson:"sha_256_hash"`
LLMCategorized bool `bson:"llm_categorized"`
DateAdded time.Time `bson:"date_added"`
DateUpdated time.Time `bson:"date_updated,omitempty"`
DateRemoved time.Time `bson:"date_removed,omitempty"`
IsRemoved bool `bson:"is_removed,omitempty"`
}
In practice, one of these documents may resemble:
{
"_id": "aggregation-tutorials",
"code_nodes_total": 3,
"date_added": 2025-02-21T02:49:52.760+00:00,
"date_last_updated": 2025-03-22T00:27:20.888+00:00,
"io_code_blocks_total": 0,
"languages": [
{
"csharp": {
"literal_includes": 0,
"io_code_block": 0,
"total": 0
}
},
{
"javascript": {
"literal_includes": 1,
"io_code_block": 0,
"total": 2
}
},
{"...other languages here..."}
],
"literal_includes_total": 1,
"nodes": [
{
"code": "const { MongoClient } = require('mongodb');",
"language": "javascript",
"file_extension": ".js",
"category": "Usage example",
"sha_256_hash": "3149663a6...",
"llm_categorized": true,
"date_added": 2025-02-21T02:49:52.760+00:00,
},
{"...other code examples here..."}
],
"page_url": "https://live.docs.page.url",
"project_name": "node",
"product": "Drivers",
"keywords": [
"node.js", "code example", "runnable app"
]
}
As you can see, this particular page has 3 code examples total, with one of them included using a special reStructuredText directive (literalinclude). The tooling added page during the first audit in February, and most recently updated the page in March. There are some keywords associated with this page - "node.js", "code example", and "runnable app".
The code example that we can see in the nodes array is a JavaScript example, with an LLM-assigned category of "Usage example". It has an added date that coincides with the date of our first audit run, but not an updated or removed date. We can conclude the code example has no changes since we completed the first audit.
From the languages array, we can see that there are a total of two JavaScript code examples on the page, so the nodes array must contain at least one other JavaScript example. Since we can also see that there are three code examples total on the page, there must be at least one in another language. Because this documentation project is "node" and this is the "Drivers" product, I know the majority of code examples are JavaScript, so my guess would be that the remaining code example is a "text" example that probably represents the output of running one of these blocks.
The eagle-eyed readers among you will have noticed that some of the data at the page level and the code example level is repetitive.
On the page level, we store:
"languages" array that contains a count of code examples in each language, and the count of examples in each language in the specialized reStructuredText directivesOn the code example level, we also store language. Each code example has a language field, so we could iterate through all the code examples on the page to get a count of the number of code examples in each language. So why include separate fields on the page level that store these counts? Isn't that an opportunity for counts to get out of step?
This is where I benefit from having a wife who has worked as a developer for more than 20 years. Many times over the years, when discussing data models, she has pointed out that data storage is cheap. It costs me practically nothing to store those counts on the page level directly - microseconds when I am ingesting the data and the computer iterates through the examples, and basically nothing in the database since I'm only storing text and text is tiny.
However, when I'm accessing the data, having those counts available on the page level instead of having to calculate them by iterating through every code example we have, that has a perceptible performance difference. With over 35,000 code examples in our documentation, having to iterate through those and perform counts takes enough time that it is perceptible. I don't know the number of pages in our documentation offhand, but I believe it's less than 10,000 (not counting documentation page versions, which we aren't assessing for audit purposes, but which does inflate our page count by many times). Iterating through fewer than 10,000 documents to get counts is pretty basic math - rougly 3.5x fewer iterations than going through all of the code examples individually. That, combined with the fact that we access (query) the data more often than we ingest (write) it, means storing this data on the page level at the time of ingesting the code examples justifies the redundancy.
There's an additional caveat that the page-level counts reflect the number of code examples currently live on the page, whereas the code nodes array contains all of the code examples that the tooling has ingested. Writers have removed some of those code examples from the current page. I don't just remove them from the database, because we want to track and report on changes over time. Instead, I set an is_removed flag on the code example, which tells me whether an example is currently live or removed from the documentation. But reading that bool and only counting the code examples that are live whenever we run a query would also add a performance impact, so reading the live count from the page has an added performance boost.
From a maintenance perspective, the opportunity for the counts to get out of step is certainly possible when storing them in two ways. But this is what tests are for! I have tests on the tooling to confirm that I am correctly incrementing the counters under a variety of scenarios, so I feel comfortable with these redundant code paths. I also have different queries that check the counts in different ways (both from the code example nodes and from the page arrays), so I can manually confirm that these numbers match at any time by running these queries. This gives me additional peace of mind about storing this data redundantly.
Another thing you may note is that the code examples in the nodes array do not have a unique identifier. That's because there is no meaningful information available in the reStructuredText directive that we could use to form a unique identifier! Our code example reStructuredText directives resemble:
.. code-block:: text
:emphasize-lines: 8
platform :ios, '12.0'
target 'MyRealmProject' do
# Comment the next line if you don't want to use dynamic frameworks
use_frameworks!
# Pods for MyRealmProject
pod 'RealmSwift', '~>10'
end
This particular directive type, which represents the majority of our code examples, is just inline text within the page content, possibly with a few options specified. In this example, we see the language is text and we have added an :emphasize-lines: option to specify highlighting for line 8. But there's nothing here that inherently serves as a unique identifier.
Why does it matter if a code example has a unique identifier? Without a unique ID, we have no way to track whether a code example is new, updated, or removed. We just have a bunch of text blobs with no real way to compare them. This makes it much more difficult to track changes over time.
In discussing this problem with the wife over dinner one day, she pointed out we could approximate a unique identifier by creating a SHA256 hash of the code example content. There is no guarantee that this is actually unique - if we use the exact same code example on more than one page, it would have the same SHA256 hash - but I can at least tell if it's unique on the page, and use that as an approximation for whether a code example on a page is new or updated.
It's not a perfect proxy, because the SHA256 hash will change if a docs writer has, for example, opened a code example file and their linter has removed extra spaces or newlines. Then a code example will have a different SHA256 hash. We could get a bit more fancy and try to normalize it - convert it to lowercase and remove spaces, for example - but for the extra processing overhead that would introduce, I don't think it's worthwhile to capture the case where spacing or newlines change.
I think this is probably the best we can do without the code example having an inherent unique identifier.
When writing this tooling, we considered storing the data in three ways:
nodes array at the root level - i.e. storing only the code examples and their associated metadata, but none of the page-level informationEach of these models has pros and cons, but we ultimately decided to go with option three.
If we stored only the code example metadata - the counts of code examples and programming languages - we would be very limited in how we could dynamically slice the data based on new queries from leadership. Since the requirements changed multiple times while we were building this tooling, it seemed shortsighted to only capture the bare minimum data requested during initial conversations. We wanted to build something that would enable future iteration.
We could store the code examples and related metadata - the elements that are in the nodes array in the model described above. That model would look something like this:
// CodeNode captures metadata about a specific code example. The `Code` field contains the example itself.
type CodeNode struct {
Code string `bson:"code"`
Language string `bson:"language"`
FileExtension string `bson:"file_extension"`
Category string `bson:"category"`
SHA256Hash string `bson:"sha_256_hash"`
LLMCategorized bool `bson:"llm_categorized"`
DateAdded time.Time `bson:"date_added"`
DateUpdated time.Time `bson:"date_updated,omitempty"`
DateRemoved time.Time `bson:"date_removed,omitempty"`
IsRemoved bool `bson:"is_removed,omitempty"`
}
And the data for the model would resemble:
{
"code": "const { MongoClient } = require('mongodb');",
"language": "javascript",
"file_extension": ".js",
"category": "Usage example",
"sha_256_hash": "3149663a6...",
"llm_categorized": true,
"date_added": 2025-02-21T02:49:52.760+00:00,
}
By storing the code example itself, as well as its associated metadata, we would enable more dynamic querying than only capturing the metadata. For example, we could query for a count of code examples with the "Usage example" category where the code value is more than N characters or N lines. This would give us a proxy for tracking longer usage examples, which we have internally dubbed "applied usage examples" - real-world code examples that go beyond syntax to show developers examples of actually using the product in context.
However, by not framing these examples in the context of the page, we're missing some opportunities to correlate code examples with a wider set of metadata. For example, when we also consider the page, we can query for the number of code examples about a given focus area, for example, or break them down by product feature. Those types of queries are not possible when you only store the code example and its related metadata.
From a performance perspective, ingesting new data also becomes an issue if we store all of the code examples without context. In order to determine whether a code example is new or updated, I compare the SHA256 hash of each incoming code example against the SHA256 hashes that I have previously ingested. If the hashes match, it's an existing code example. If they don't match, I have some additional logic to diff the code example text to try to evaluate whether it's just an update or whether it's a net new example.
However, given the data model where we store code examples in the context of the page, I perform these calculations only in the context of that page. Given the page I'm using in this article as an example, when I ingest the new data for this page, I only have to compare N incoming code examples against the three code examples I've previously ingested. Comparing, say, five code examples against three that I've previously ingested is not a huge performance time sink. But if I did not store the code examples in the context of the page, I would have to compare every incoming code example against every other example that I have previously ingested. So for a page with 5 incoming code examples, I would have to compare each of those 5 examples against all 35,000+ code examples in my database to figure out if they were new or updated. So in the end, I would have to compare every one of the 35,000+ incoming code examples against the 35,000 existing code examples.
In computing, this is an O(n) problem. This comparison is O(n²). When the data set is 35,000 elements, that is a slow comparison. When the data set is only 3 or 5 elements, the comparison is much more performant. In our tooling, I've done additional optimizations to eliminate matched elements from comparison, and use performant data structures when comparing, to further improve performance.
Sometimes, we want to manually validate the category of a code example, or confirm that the tooling logic has correctly assesed a code example as net new versus updated. If we store the code example without the context of its corresponding page, I don't have an easy way to find that code example within our existing corpus to do a manual comparison.
With the model we're using, where we store code examples in the context of the page, I have two points of page metadata that make it easy to find the example in the context of our existing corpus:
If I need to see the source of the code example - for example, if I want to find out whether a code example was recently added or updated - I can use the identifier for the page to find the file within the documentation source where the code example originates. I can check the git history for that file, or for the specific lines of the code example, to get information about the history of those lines.
If I just want to confirm that the code example is live on the page, or get information about surrounding page context, I can quickly copy the live documentation page URL into my browser and find the code example on the page. No need to go hunting in the source for the file where the example originates.
In both of these cases, storing the code examples in the context of their corresponding pages streamlines manual validation. If I wanted to manually validate a code example stored without page context, I'd have to grep across ~39 different repositories where the docs souce is currently stored to find the text in the code example, and potentially sift through matches to find the one I want - or be unable to confirm which match I'm looking for because I'm lacking source metadata to give me context.
As I've covered above, storing the code examples in the context of their documentation pages enables some nice benefits:
It also enables future iteration, which I'll cover next.
But as with all technical decisions, it has downsides. The notable one that we have encountered so far is a common case in documentation sets: it has implications when it comes to restructuring documentation pages.
When I do the comparison of incoming code examples to existing examples to determine whether they are net new or updated, I compare them only at the page level. When we move content around between pages, I have no way to know that these N code examples removed from page FOO are the same N code examples added to page BAR. For example, the tooling shows 5 code examples as removed, and 5 net new code examples added to a different page. It has no concept of "moved" code examples. So I get false positives when calculating "new" code examples.
I could modify the tooling to store removed code examples outside of the context of their corresponding pages, and then compare "new" incoming code examples against removed examples to figure out if they are truly net new or just moved. There are probably edge cases that I haven't thought through related to this, since I haven't implemented it yet. But I think the number of moved code examples is probably low enough that it won't be a huge performance hit to do that additional comparison for "new" incoming code examples.
This is an improvement I would like to make to the tooling, but as with any tooling - maintaining and improving this tooling isn't exactly my job. This audit was originally pitched as a one-time thing. Leadership then asked us to create the capability to re-run the tooling, but that wasn't work that we had scoped. I spent a couple of weeks building our one-time hacked-together pipeline that existed in three different code bases into a unified tool that we could re-run regularly. But there was time pressure to be "done", and it's hard to justify going back to add or change functionality in something that isn't our primary directive.
I'll add this to the list of future improvements, but probably won't get to spend time on it unless/until leadership decides that the false positives matter enough to actually address this.
The thing I like most about this data model - storing code examples in the context of their pages - is how well it enables future iteration. Since building this tooling and running the initial audit, we have continued to get new requests from leadership to slice the data in different ways. For example, these fields in the data model were not present in our initial tooling:
As we have continued to get requests from leadership to be able to report on our code examples in different ways, I have added metadata on the page level with very little effort to enable these new queries and reports.
We also have plans for future iteration. For example, our organization has a concept of the "top 250" documentation pages across our documentation sets. These pages are high-impact or have a high number of visitors, so they become a priority when we get feedback about issues, or need to make changes for SEO or other reasons. My team has discussed adding the "top 250" information to our database, so we can report on code examples across the top 250 pages. We can also potentially use this to plan and report on code example standardization and testing projects around these pages.
I expect there will be many more cases where we get requests to report on our code examples in different ways, and this data structure will enable the iteration required to trivially address those requests.
I've covered some of the queries we've used in this article as I've discussed what our data model has enabled. I've had fun slicing the data in really interesting ways. I'll cover that in more detail in the Slicing code example metadata article. Then, I'll deep dive into some of the most interesting results of our findings in the Audit conclusions article. And finally, I'll wrap things up with information about how we are now running this tooling on a weekly basis and using it to report to leadership about changes to our code examples over time in the Ongoing code example reporting article (coming soon).
In which I validate a 23.7k-star skill mega repo and discover problems the star count won't tell you.
In which I show you how I made multiple Hugo sites agent-friendly.
In which I deep dive on a Stripe Skill, and what it means for the industry.


{kind=link}